【概述】
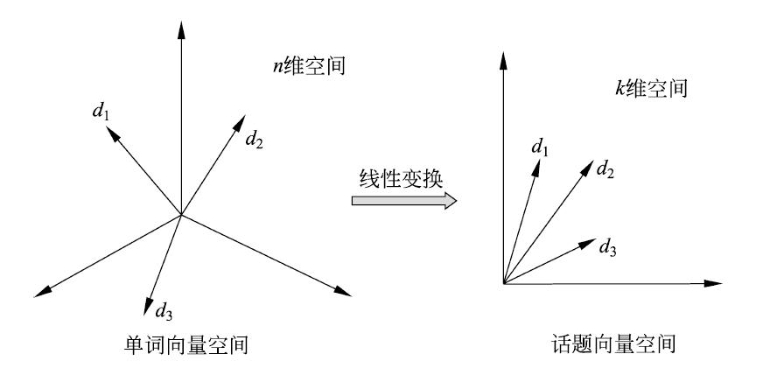
潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)是文本集合的生成概率模型,其假设话题由单词的多项分布表示,文本由话题的多项分布表示,单词分布和话题分布的先验分布都是狄利克雷分布,文本内容不同是由于它们的话题分布不同
LDA 模型表示了文本集合自动生成过程:首先,基于单词分布的先验分布(狄利克雷分布)生成多个单词分布,即决定多个话题内容;之后,基于话题分布的先验分布(狄利克雷分布)生成多个话题分布,即决定多个文本内容;最后,基于每一个话题分布生成话题序列,针对每一个话题,基于话题的单词分布生成单词,整体构成一个单词序列,即生成文本,重复这个过程生成所有文本