【概述】
在 NLP 的任务中,独热编码(One-Hot Encoding)是最简单的词嵌入方式,其能将文本转化为向量形式表示,并且不局限于语言种类
同时,在机器学习与深度学习的任务中,One-Hot 编码也能够来表征离散特征取值没有大小意义的特征
【编码原因】
One-Hot 编码起源于机器学习和深度学习,对于特征或分类标签是离散特征编码的情况,其常分为两类:
- 离散特征的取值有大小意义,例如:
size[S, M, X, XL], - 离散特征的取值没有大小意义,例如:
color[red, white]
对于第一种情况来说,可使用数值特征的映射 {S:1, M:2, X:3},而对于第二种情况,需要一种编码,将相互独立的特征表示为相互独立的数字,且数字间的距离也相等
而 One-Hot 编码就是一种用二进制向量来表征离散特征取值没有大小意义的编码方式,其将离散特征的取值扩展到了欧氏空间,离散特征的某个取值就对应欧氏空间中的某个点
同时,使用 One-Hot 编码后的特征向量,能够看作是连续的特征,此时可以与连续型特征的归一化方法相同,进行归一化
【编码方式】
One-Hot 的编码方式是将具有 $n$ 个状态的离散特征用长度为 $n$ 的二进制向量表示,当前维度被标记为 $1$,表示当前特征,其他维度标记为 $0$
在 NLP 中,对于大小为 $n$ 的词典,会将词典中的所有词排成一列,根据单词的位置设计向量,则每个单词会表示为一个为 $n$ 维的向量,单词对应词典中的位置的维度标记为 $1$,其他位置标记为 $0$
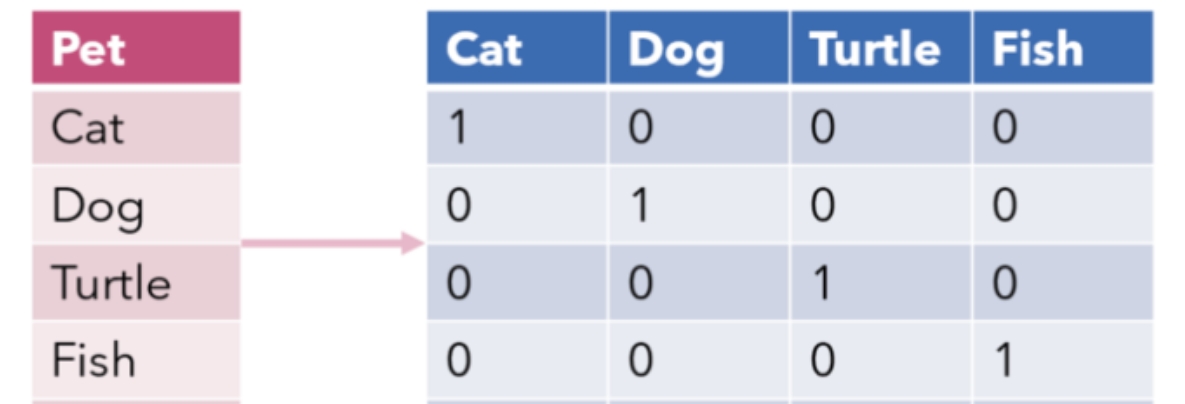
举例来说,有一个离散特征 Pet,其可能的取值为 cat、dog、turtle、fish,经过 One-Hot 编码后,其表征如下图
【存在问题】
One-Hot 编码虽然简单,并且适用于任意文本数据,但存在很多严重问题:
- 维度爆炸:由于每一个单词的词向量的维度都等于词汇表的长度,对于大规模语料训练的情况,词汇表将异常庞大,使模型的计算量剧增造成维数灾难
- 矩阵稀疏:有用的信息零散地分布在大量数据中,这会导致结果异常稀疏,使其难以进行优化,对于神经网络来说尤其如此
- 向量正交:由于两两向量正交,无法表达两词向量之间的其他信息,造成了语义鸿沟的现象
所以,One-Hot 编码可以认为只是简单地将词进行了编号,并没有表达词语的含义,并不符合语言的自然规律
【Sklearn 实现】
1 | from sklearn.feature_extraction.text import CountVectorizer |

