Reference
【概述】
对数几率回归(Logistic regression)即 Logistic 回归,虽然名为回归,但其实际上是一种解决分类问题的分类学习方法,在现实中应用十分广泛,比如垃圾邮件识别,手写数字识别,人脸识别,语音识别等
对于分类问题来说,如果利用线性回归来拟合,假设函数 $f(\mathbf{x_i};\boldsymbol{\theta})$ 的输出值会出现 $f(\mathbf{x_i};\boldsymbol{\theta})>1$ 或 $f(\mathbf{x_i};\boldsymbol{\theta})<0$ 的情况,无法对结果进行归纳,因此,有了 Logistic 回归
其利用一个单调可微的激活函数,将分类任务的真实标记 $y_i$ 与线性回归模型的预测值 $f(\mathbf{x_i};\boldsymbol{\theta})$ 联系起来,从而将数值结果转换为分类结果,简单来说,其是利用线性回归模型的预测结果去逼近真实标记的对数几率
Logistic 回归根据分类数据的类别,分为以下三种情况:
- 二元 Logistic 回归:分类数据为两类(例如:有/没有)
- 多元无序 Logistic 回归:分类数据超过两类,且类别间没有对比意义(例如:一线城市、二线城市、三线城市)
- 多元有序 Logistic 回归:分类数据超过两类,且类别间有对比意义(例如:喜欢、不喜欢、无所谓)
需要注意的是,这里的元,指的不是自变量的个数,而是因变量的取值范围
本文仅介绍二元 Logistic 回归,关于多元 Logistic 回归,详见:多元 Logistic 回归
【假设形式】
假设函数
对于给定的容量为 $n$ 的样本集 $D=\{(\mathbf{x_1},y_1),(\mathbf{x_2},y_2),…,(\mathbf{x_n},y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x_i}$ 具有 $m$ 个特征值,即:$\mathbf{x_i}=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出为 $y_i\in \{0,1\}$,二元 Logistic 回归学习到的模型为 $f(\mathbf{x_i};\boldsymbol{\theta})$,使得 $f(\mathbf{x_i};\boldsymbol{\theta})\simeq y_i$
假设函数 $f(\mathbf{x_i};\boldsymbol{\theta})$ 为:
其中,特征参数 $\boldsymbol{\theta}$ 为 $(m+1)\times 1$ 的列向量,即:
$g(z)$ 为激活函数,就是假说表示,对于不同的问题,根据实际情况来选择不同的激活函数
为了表述方便,对假设函数进行简化,定义一个额外的第 $0$ 个特征量,这个特征量对所有样本的取值全部为 $1$,这使得特征量从过去的 $m$ 个变为 $m+1$ 个,即设:$x_i^{(0)}=1$
那么假设函数就可以写为:
在二元 Logistic 回归中,采用 sigmoid 函数 $\sigma(z)=\frac{1}{1+e^{-z}}$ 作为激活函数,其图像如下:
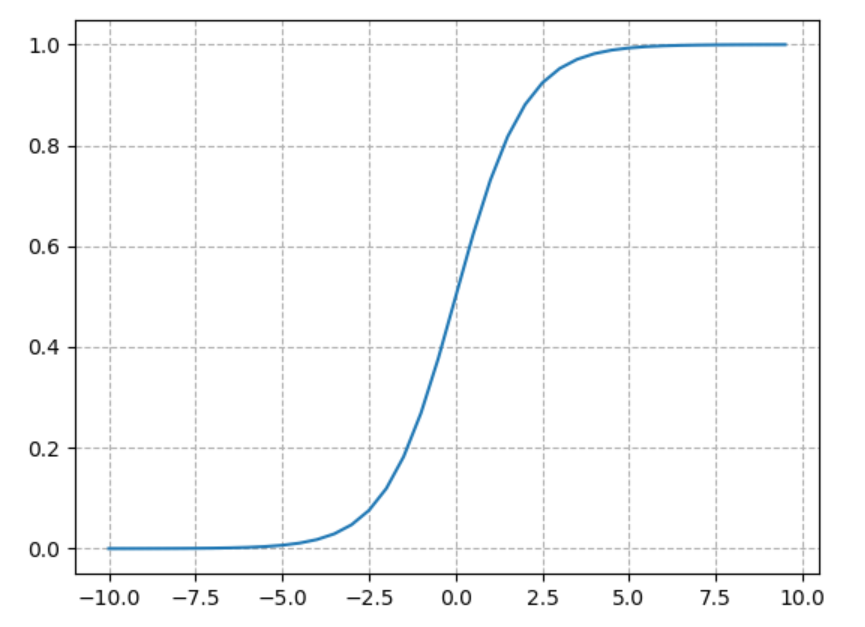
不难看出,sigmoid 函数左侧无限接近于 $0$,右侧无限接近于 $1$,具有很好的对称性,值域 $y \in (0,1)$,正好符合对二分类问题模型的要求
于是,假设函数可以写作:
对数几率形式
对于假设函数 $f(\mathbf{x_i};\boldsymbol{\theta})=\frac{1}{1+e^{-\boldsymbol{\theta}^T\mathbf{x_i}}}$,将假设函数 $f(\mathbf{x_i};\boldsymbol{\theta})$ 的值 $\hat{y_i}$ 记为样本 $\mathbf{x_i}$ 为正例的可能性,则 $1-\hat{y_i}$ 是其为反例的可能性,则两者的比值,称为几率(Odds),其反映了 $\mathbf{x_i}$ 作为正例的相对可能性:
当假设输出标记 $\hat{y_i}$ 是在指数尺度上变化时,可对几率取对数,称为对数几率(Log Odds),即:
将对数几率作为模型逼近的目标,并将假设函数带入,即二元 Logistic 回归模型的对数几率形式:
若将 $\hat{y_i}$ 视为后验概率估计 $P(y_i=1|\mathbf{x_i};\boldsymbol{\theta})$,即在给定概率参数为 $\boldsymbol{\theta}$ 时,对具有 $\mathbf{x_i}$ 特征的条件下 $y_i=1$ 时的概率,即:
那么对于二分类问题,由于输出值非 $0$ 即 $1$,故而可计算出 $y_i=0$ 的概率,即:
那么对数几率可写为:
后验概率形式
对于对数几率 $\ln \frac{P(y_i=1|\mathbf{x_i};\boldsymbol{\theta})}{P(y_i=0|\mathbf{x_i};\boldsymbol{\theta})}=\boldsymbol{\theta}^T\mathbf{x_i}$ 中的 $P(y_i=1|\mathbf{x_i};\boldsymbol{\theta})$ 有:
进而可得:
即:
由于 $y_i$ 只能取 $0$ 或 $1$,那么可以将上面两个式子合写为一个,即二元 Logistic 回归模型的后验概率形式:
【损失函数】
引入
在多元线性回归模型中,当批量使用梯度下降法求解时,损失函数为:
在二元 Logistic 回归中,将假设函数 $\hat{y_i}=\frac{1}{1+e^{-\boldsymbol{\theta}^T\mathbf{x_i}}}$ 带入上述的代价函数里,并画出代价函数的图像,会发现可能是一个类似下图的非凸函数,即有许多局部最优值,如果将梯度下降法用在这样一个函数上,无法保证其能收敛到全局最小值
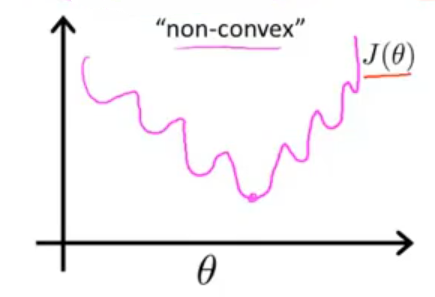
因此,为了保证使用梯度下降法使得代价函数收敛到全局最小值,代价函数需要是一个凸函数,那么就要另找一个不同的代价函数
损失函数
对于得到的二元 Logistic 回归模型的后验概率形式:
采用最大似然法(Maximum Likelihood Method)来估计 $\boldsymbol{\theta}$,即对于给定的容量为 $n$ 的训练集 $D=\{(\mathbf{x_1},y_1),(\mathbf{x_2},y_2),…,(\mathbf{x_n},y_n)\}$,可得到似然函数:
在 $\boldsymbol{\theta}$ 的所有可能取值中找一个使得似然函数取到最大值,这时求得的解就是最大似然估计,即:
由于带连乘运算的似然函数 $L(\boldsymbol{\theta})$ 不好优化,考虑到似然函数的取值范围为 $(0,1)$,那么对似然函数取自然对数不影响其单调性,同时为将最大化问题转为最小化问题,再对取自然对数后的似然函数进行取反,这样就得到了二元 Logistic 回归的损失函数:
此时的损失函数 $J(\boldsymbol{\theta})=-\sum\limits_{i=1}^n \big[ y_i \ln \hat{y_i} + (1-y_i) \ln (1-\hat{y_i}) \big] $,就是整个训练集的损失函数
下面继续对损失函数 $J(\boldsymbol{\theta})$ 进行化简,考虑使用对数几率 $\ln \frac{\hat{y_i}}{1-\hat{y_i}}=\boldsymbol{\theta}^T\mathbf{x_i}$ 进行表示,则有:
即:
接下来要做的,就是要最小化代价函数,为训练集拟合出参数,即:
【批量梯度下降法求解】
使用批量梯度下降法来最小化代价函数:
即将下列公式重复直到收敛为止:
关于批量梯度下降法的具体介绍,详见:梯度下降法
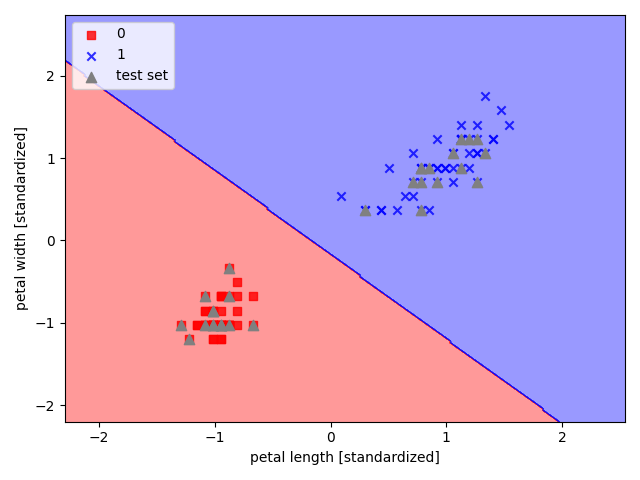
【决策边界】
决策边界(Decision Boundary)是分类问题中假设函数的一个属性,其决定于 $\boldsymbol{\theta}$ 参数,一旦通过训练集拟合出了 $\boldsymbol{\theta}$ 参数,就确定了决策边界
首先来看假设函数:
接着给出 sigmoid 函数的图像,来看一下假设函数何时会预测 $y=0$,何时又会预测 $y=1$
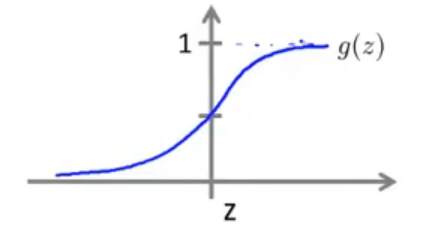
根据 sigmoid 函数图像的对称性,可以认为,只要假设函数输出 $y=1$ 的概率大于或等于 $0.5$,那么意味着 $y=1$,相反地,只要假设函数输出 $y=0$ 的概率小于 $0.5$,那么意味着 $y=0$,即:
也就是说,只要 $\boldsymbol{\theta}^T\mathbf{x_i} \geq 0$,那么 $\hat{y_i} \geq 0.5$,就预测 $y=1$,同理,只要 $\boldsymbol{\theta}^T\mathbf{x_i} < 0$,那么 $\hat{y_i} < 0.5$,就预测 $y=0$
而决策边界,是一条直线,其将预测值为 $1$ 和 $0$ 的两个区域分隔开来,这一条线对应的就是 $\hat{y_i}=0.5$,即 $\boldsymbol{\theta}^T\mathbf{x_i}=0$ 时所对应的线
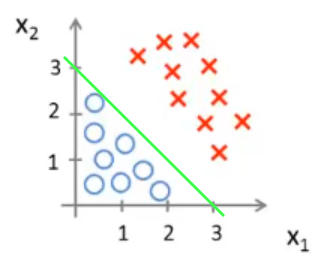
如下图,假设有一个存在两个特征的模型:$\hat{y_i}=g(\theta_0+\theta_1x_1+\theta_2x_2)$
通过训练集拟合出的 $\boldsymbol{\theta}=[-3,1,1]^T$,则:
当 $\boldsymbol{\theta}^T\mathbf{x_i} \geq 0$,即:$-3+x_1+x_2 \geq 0$ 时,模型预测 $y=1$
当 $\boldsymbol{\theta}^T\mathbf{x_i} < 0$,即:$-3+x_1+x_2 < 0$ 时,模型预测 $y=0$
此时,$x_1+x_2=3$ 就是该模型的决策边界
【sklearn 实现】
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征实现二元 Logistic 回归
1 | import pandas as pd |

