【概述】
目前,结构化查询语言 SQL 是关系数据库的标准语言,也是一个通用的、功能极强的关系数据库语言,其功能不仅仅是查询,还包括数据库模式创建、数据库数据更新、数据库安全性完整性定义与控制等功能
在 关系操作 中,简单介绍了关系数据语言,本篇将对 SQL 进行简单的介绍
【特点】
综合统一
数据库系统的主要功能是通过数据库支持的数据语言来实现的,对于非关系模型的数据语言,分为以下四类:
- 模式数据定义语言(模式 DDL):用于定义模式
- 外模式数据定义语言(外模式 DDL):用于定义外模式
- 数据存储描述语言(DSDL):用于定义内模式
- 数据操纵语言(DML):进行数据的存取与处置
当非关系模型的用户数据库投入运行后,如果要修改模式,必须停止现有数据库的运行,转储数据,修改模式编译后再重装数据库,十分繁琐
而 SQL 集数据定义语言(DDL),数据操纵语言(DML),数据控制语言(DCL)功能于一体,语言风格统一,可以独立完成数据库生命周期中的全部活动:
- 数据定义(DDL):
- 定义、修改、删除关系模式(基本表)
- 定义、删除视图
- 定义、删除索引
- 数据操纵(DML):
- 数据查询
- 数据插入、删除、更新
- 数据控制(DCL):
- 用户访问权限的授予、收回
这为数据库应用系统的开发提供了良好的环境,尤其是在关系模型的用户数据库投入运行后,当修改模式时,可根据需要随时修改模式,不影响数据库的运行,使数据库具有良好的可扩展性
此外,由于关系模型中,实体与实体间的联系均用关系来表示,这种数据结构的单一性使得 SQL 中的数据操作符具有统一性
高度非过程化
在非关系模型中,数据操纵语言(DML)是面向过程的语言,在完成某些请求时必须指定存取路径
而用 SQL 进行数据操纵时,用户只要提出要做什么,无须了解存储路径,由系统自动完成存取路径的选择和 SQL 具体的操作过程
SQL 的这种设计,不仅减轻了用户的负担,还利于提高数据独立性
集合操作方式
在非关系模型中,采用的是面向记录的操作方式,操作对象是一条记录,在操作时通常要说明具体处理过程,即按照哪条路径、如何循环等
而 SQL 采用集合操作方式,不仅操作对象、查找结果是元组的集合,每次插入、删除、更新操作的对象也是元组的集合
多种使用方式
SQL 既是独立语言,又是嵌入式语言,在这两种不同的使用方式下,语法结构基本上是一致的,这种统一的语法结构提供多种不同使用方式的做法,提供了极大的灵活性与方便性
作为独立语言,其能独立交互使用,一般由 DBMS 提供联机交互工具,用户可以在终端上直接键入 SQL 命令对数据库进行操作,由 DBMS 来进行解释
作为嵌入式语言,SQL 语句能够嵌入到高级语言程序(宿主语言)中,供程序员设计程序时使用,使得应用程序能够充分利用 SQL 访问数据库的能力与宿主语言的过程处理能力,此外,一般需要进行预编译,将嵌入的 SQL 语句转化为宿主语言编译器能处理的语句
语言简洁
SQL 功能极强,语言十分简洁,核心功能只有 9 个动词,接近英语口语,易于学习和使用
| SQL 功能 | 动词 |
|---|---|
| 数据查询 | SELECT |
| 数据定义 | CREATE、DROP、ALTER |
| 数据操纵 | INSERT、UPDATE、DELETE |
| 数据控制 | GRANT、REVOKE |
【对三级模式结构的支持】
支持 SQL 的关系数据库管理系统同样支持数据库三级模式结构
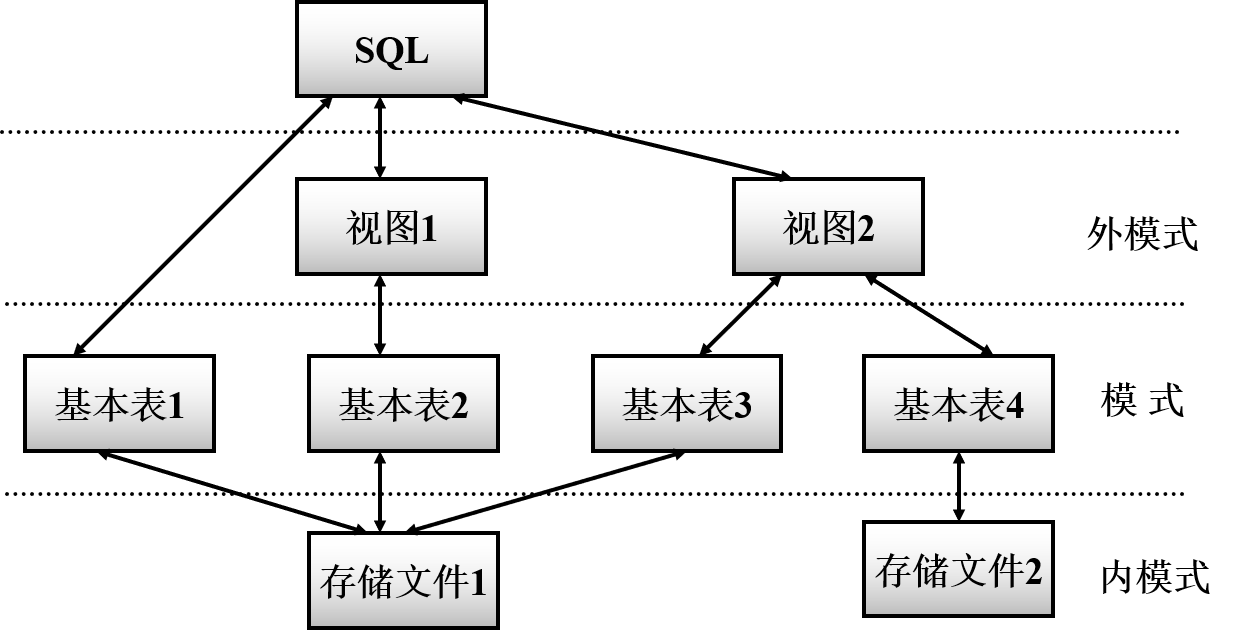
基本表是本身独立存在的表,在关系型数据库中,一个关系就对应一个基本表,一个或多个基本表对应一个存储文件,此外,一个表也可以携带若干索引,索引也存放在存储文件中
视图是从一个或几个基本表导出的表,其是一个虚表,本身不独立存储在数据库中,在数据库中仅存放其定义而不存放其对应的数据,其在概念上与基本表等同,用户可以在视图上再定义视图
存储文件的逻辑结构组成了关系数据库的内模式,物理结构对用户是透明的
【数据定义】
定义语句
由于支持 SQL 的关系数据库系统支持三级模式结构,其模式、外模式、内模式中的基本对象有:模式、表、视图、索引,因此 SQL 的数据定义功能包括模式定义、表定义、视图定义、索引定义
相关的定义语句如下表
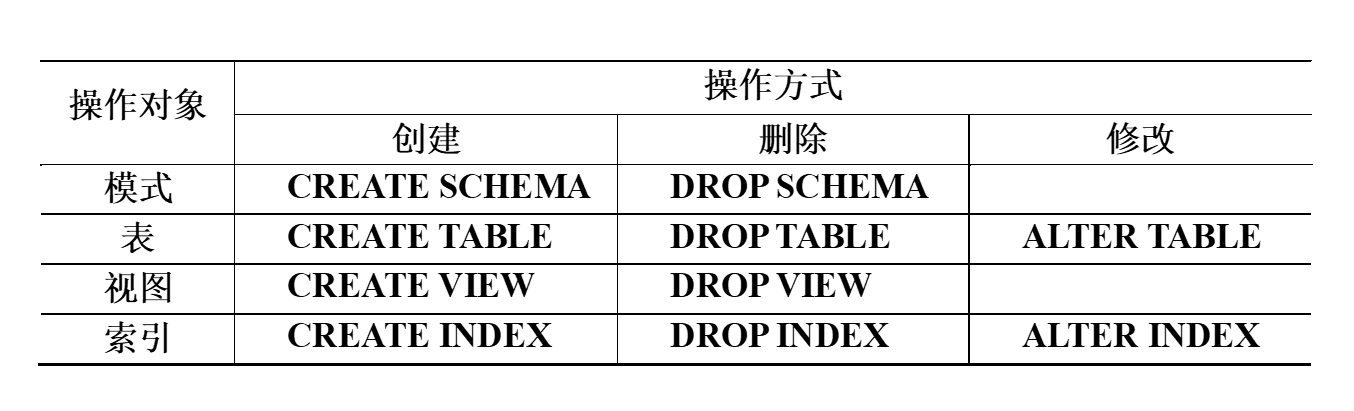
可以看到,SQL 标准不提供修改模式定义和修改视图定义的操作,用户如果想修改这些对象,只能先删除后重建,实际上,SQL 标准也没有提供索引相关的语句,但为提高查询效率,商用关系数据库管理系统通常都提供了索引及其相关的语句
层次结构
在早期的数据库系统中,所有数据库对象都属于一个数据库,即只有一个命名空间,而现代的数据库管理系统提供了一个层次化的数据库对象命名机制,即对于一个关系管理数据库系统的实例,可以建立多个数据库;在一个数据库中,可以建立多个模式;在一个模式下,可以多个数据库对象(表、视图、索引)
关于数据定义的详细介绍见下
数据字典
在 RDBMS 中,系统内部有一组系统表,被称为数据字典,其记录了数据巨亏中所有的定义信息,包括关系模式定义、视图定义、索引定义、完整性约束定义、各类用户对数据库的操作权限、统计信息等,RDBMS 在执行 SQL 的数据定义语句时,实际上就是在更新数据字典中的相应信息
【数据查询】
查询语句
数据查询是数据库的核心操作,SQL 提供了 SELECT 语句进行数据查询,该语句具有灵活的使用方式和丰富的功能,其一般格式为:
1 | SELECT [ALL|DISTINCT] <目标列表表达式1> [,<目标列表表达式2> ... <目标列表表达式n>] |
语句含义
整个 SELECT 语句的含义是:
- 从
FROM子句指定的基本表、视图、派生表作笛卡尔积 - 根据
WHERE子句的条件表达式,进行选择运算,找出符合条件的元组 - 根据
SELECT子句中的目标列表表达式,对上述结果作投影运算,形成结果表 - 如果有
GROUP BY子句,则将结果按<列名1>的值进行分组,该属性列值相等的元组为一组,通常会在每组中作用聚集函数,如果带有HAVING短语,则按照其<条件表达式>,满足其指定条件的组才予以输出 - 如果有
ORDER BY子句,则结果表还要按照<列名2>的值,进行升序ASC或降序DESC排序
具体用法
SELECT 语句既可以完成简单的单表查询,也可以完成复杂的连接查询,关于数据查询的基本用法详细介绍见下:
数据库
为更好的进行演示,演示数据库采用学生课程数据库 S-T,包含三张表:
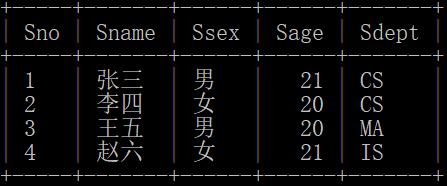
- 学生表 student:学号 Sno、姓名 Sname、性别 Ssex、年龄 Sage、系 Sdept
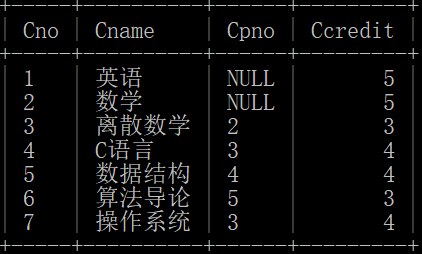
- 课程表 course:课程号 Cno、课程名 Cname、先修课课程号 Cpno、学分 Ccreadit
- 选课关系表 sc:学号 Sno、课程号 Cno、成绩 Grade
各表中的数据如下:
学生表:student(Sno, Sname, Ssex, Sage, Sdept)
课程表:course(Cno, Cname, Cpno, Ccredit)
选课关系表:sc(Sno, Cno, Grade)
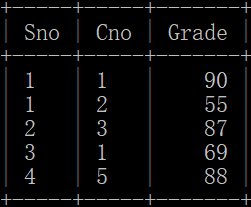
SQL 如下:
1 | SET FOREIGN_KEY_CHECKS=0; |
【数据更新】
数据更新操作有三种:插入数据、修改数据、删除数据
详细介绍见下:
对于视图的更新:点击这里
【空值的处理】
所谓空值 NULL 就是不知道、无意义、不存在的值,SQL 语言中允许某些元组的某些属性在一定情况下取空值,一般有以下几种情况:
- 该属性有一个值,但目前不知道它的具体值
- 该属性不应该有值
- 由于某种原因不便填写
综上所述,空值是一个很特殊的值,含有不确定性,对关系运算带来特殊的问题,因此需要进行特殊处理
关于空值的处理详见:SQL 的空值处理

