【ORDER BY 子句】
基本使用
ORDER BY 子句用于对查询结果按照一个或多个属性列进行升序 ASC 或降序 DESC 排序,默认为升序
例如,查询选修了 1 号课程的学生的学号及其成绩,查询结果按照分数降序排列

空值处理
当排序列出现空值 NULL 时,显示的次序将由具体的 RDBMS 决定,一般来说,若按升序 ASC 排序,空值元组最后显示,若按降序 DESC 排序,空值元组最先显示
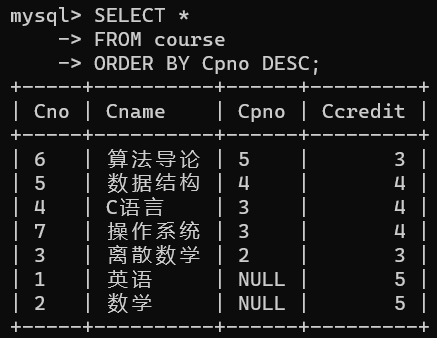
例如,查询所有课程情况,查询结果按先修课程号降序排列
【聚集函数】
常见聚集函数
为方便用户,增强检索功能,SQL 提供了许多聚集函数,常用的有:
- 将字母转为小写:
LOWER(<列名>) - 将字母转为大写:
UPPER(<列名>) - 统计元组个数:
COUNT(*) - 统计一列中值的个数:
COUNT([DISTINCT|ALL] <列名>) - 计算一列值的和:
SUM([DISTINCT|ALL] <列名>) - 计算一列值的平均值:
AVG([DISTINCT|ALL] <列名>) - 求一列值中的最大值:
MAX([DISTINCT|ALL] <列名>) - 求一列值中的最小值:
MIN([DISTINCT|ALL] <列名>)
需要说明的是,在 WHERE 子句中,聚集函数不能作为条件表达式,其只能作用于 SELECT 子句和 GROUP BY 中的 HAVING 短语里
基本使用
如果指定了 DISTINCT 短语,则在计算时会取消指定列中的重复值;如果不指定 DISTINCT 短语,将默认采用 ALL 短语,在计算时会不取消重复列值
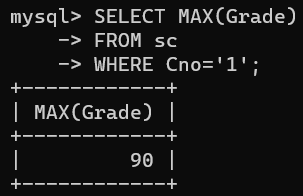
例如,查询选修 1 号课程的学生的最高分数
空值处理
当聚集函数遇到空值时,除 COUNT(*) 外,其他的聚集函数一般都跳过空值
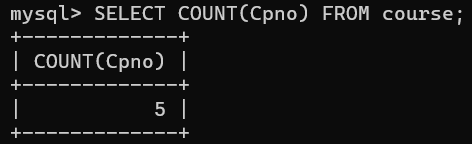
例如,查询所有不需要先修课的课程个数
【GROUP BY 子句】
基本使用
GROUP BY 子句将查询结果按某一列或多列的值分组,值相等的分为一组
对查询结果分组的目的是为了细化聚集函数的作用对象,分组后的聚集函数将作用于每一个组,即每一组都有一个函数值
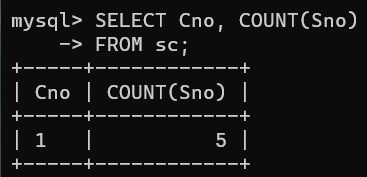
例如,查询各个课程号及相应的选课人数

如果未使用 GROUP BY 子句,聚集函数将作用于整个查询结果,显示将不完整
HAVING 短语
如果分组后还要求按照一定的条件对这些组进行筛选,最终只输出满足条件的组,此时需要使用 HAVING 短语进行指定
WHERE 子句与 HAVING 短语的区别在于两者的作用对象不同,WHERE 子句作用于基本表或视图,从中选择满足条件的元组,HAVING 短语作用于组,从中选择满足条件的组
当选用了 HAVING 短语后,其执行顺序是,先用 GROUP BY 子句按指定列进行分组,再将分组结果作为一个中间表,执行 HAVING 短语后的聚集函数
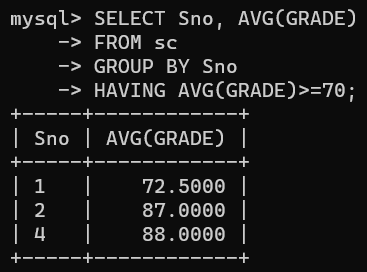
例如,查询平均成绩大于等于 70 分的学生学号和平均成绩