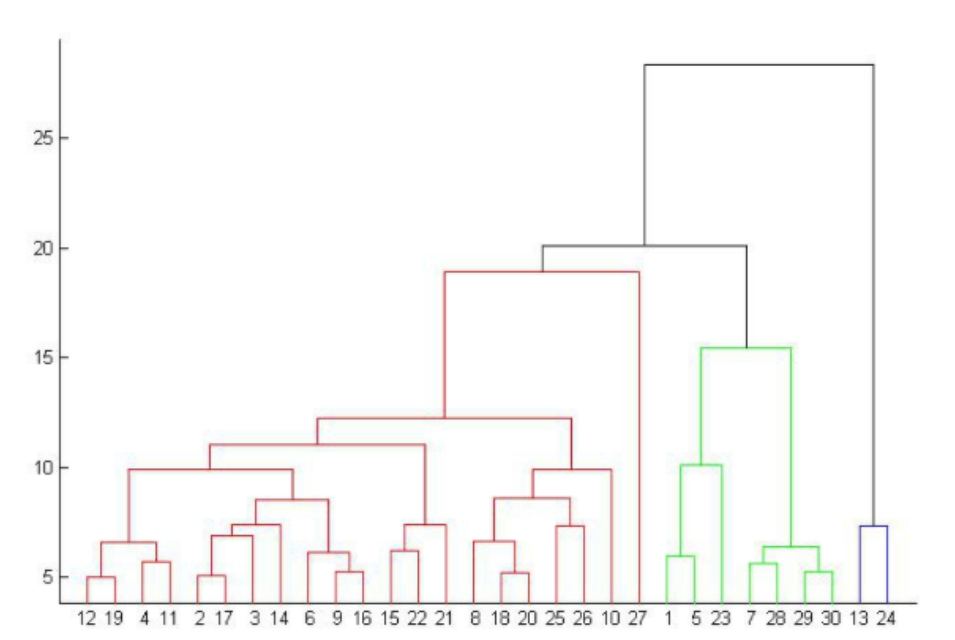
【概述】 层次聚类(Hierarchical Clustering) 假设类别之间存在层次结构,将样本聚类到层次化的簇中,由于每个样本只属于一个簇,因此层次聚类属于硬聚类
其是通过计算不同类别的数据点间的相似度,来创建一棵有层次的嵌套聚类树,在聚类完成后,可在任意层次进行切分,以得到指定数目的簇
层次聚类距离和规则的相似度容易定义,限制较小,而且不需要预先指定聚类的簇数,同时可以发现簇间的层次关系,但是其计算复杂度较高,奇异值会造成较大影响,算法最终可能会聚类成链状
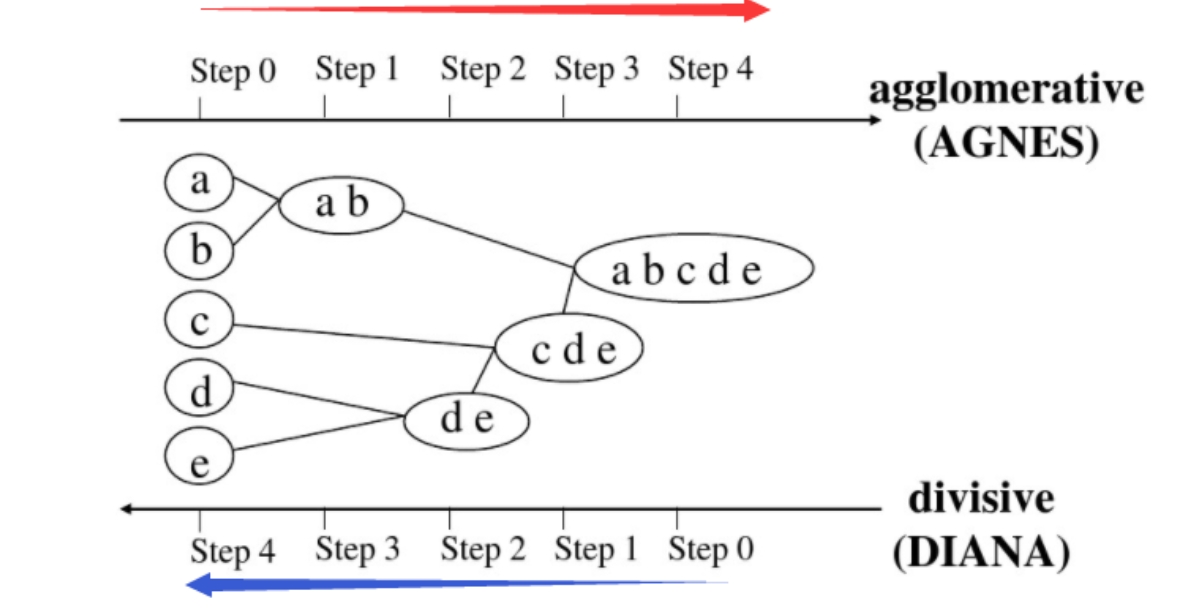
【基本原理】 按照层次分解是自下而上,还是自上而下,层次聚类方法可分为以下两种:
自下而上的凝聚(Agglomerative)方法 :将数据集的每个样本点都看成一个簇,然后找出距离最小的两个簇进行合并,不断重复到预期簇或者其他终止条件自上而下的分裂(Divisive)方法 :将数据集的样本点当作一整个簇,然后找出簇中距离最远的两个簇进行分裂,不断重复到预期簇或者其他终止条件
凝聚方法的代表算法是凝聚嵌套(Agglomerative Nesting,AGNES)算法 ,分裂方法的代表算法是分裂分析(Divisive Analysis,DIANA)算法 ,两者的聚类图示如下
综上,可以发现层次聚类需要预先确定如下三个要素:
距离
合并/分裂规则
停止条件
根据以上三个要素的不同组合,就可以构造出不同的层次聚类方法
一般来说,距离可以是欧氏距离、相关系数、余弦距离等;合并/分裂规则通常是簇间距离最小/最大,而簇间距离可以是最短距离、最长距离、中心距离、平均距离等;停止条件可以是簇的个数达到阈值、簇的直径超过阈值等
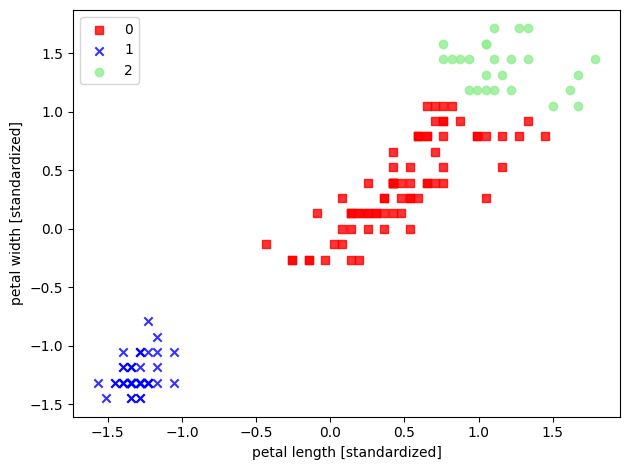
【sklearn 实现】 以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现利用 AGNES 聚类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.preprocessing import StandardScalerfrom sklearn.cluster import AgglomerativeClusteringfrom scipy.spatial.distance import cdistfrom matplotlib.colors import ListedColormapdef deal_data (): iris = load_iris() X = iris.data[:, [2 , 3 ]] return X def standard_scaler (X ): sc = StandardScaler() scaler = sc.fit(X) X_std = scaler.transform(X) return X_std def train_model (features, k ): model = AgglomerativeClustering(linkage='ward' , n_clusters=k) model.fit(features) return model def visualization (X, y ): markers = ('s' , 'x' , 'o' , '^' , 'v' ) colors = ('red' , 'blue' , 'lightgreen' , 'gray' , 'cyan' ) cmap = ListedColormap(colors[:len (np.unique(y))]) for idx, cl in enumerate (np.unique(y)): plt.scatter(x=X[y == cl, 0 ], y=X[y == cl, 1 ], alpha=0.8 , c=cmap(idx), marker=markers[idx], label=cl) plt.xlabel('petal length [standardized]' ) plt.ylabel('petal width [standardized]' ) plt.legend(loc='upper left' ) plt.tight_layout() plt.show() if __name__ == "__main__" : X = deal_data() X_std = standard_scaler(X) k = 3 model = train_model(X_std, k) label_pred = model.labels_ visualization(X_std, label_pred)