Reference
【朴素贝叶斯参数估计】
对于朴素贝叶斯分类器:
模型学习意味着对类先验概率 $P(Y=c_k)$ 与似然概率 $P(X^{(j)}=x^{(j)}|Y=c_k)$ 进行参数估计,此时,可以使用极大似然估计来进行参数估计
由于离散型随机变量是直接将频率当做概率,因此若一个属性未出现时,计算得出的概率为 $0$
为避免这种错误,可以使用贝叶斯估计,通过引入 $\lambda=1$ 进行拉普拉斯平滑修正,即假设特征值和类别的均匀分布,但当样本数目足够大时,该影响会被消除
【极大似然估计】
朴素贝叶斯的学习就意味着对类先验概率 $P(Y=c_k)$ 与似然概率 $P(X^{(j)}=x^{(j)}|Y=c_k)$ 进行参数估计
对于类先验概率 $P(Y=c_k)$,可以通过对训练集进行经验统计而得出,对于样本容量为 $n$ 的训练集,有:
对于似然概率 $P(X^{(j)}=x^{(j)}|Y=c_k)$,根据贝叶斯公式,可写为:
对于分子,根据条件概率公式,有:
假设第 $j$ 个特征 $x^{(j)}$ 可能取值的集合为 $\{a^{(j)}_1,a^{(j)}_2,…,a^{(j)}_{S_j}\}$,其中,$a^{(j)}_l$ 代表第 $j$ 个特征可能取的第 $l$ 个值,$S_j$ 代表第 $j$ 个特征可取值的数量,那么有:
其中,$j=1,2,…,n$,$l=1,2,…,S_j$,$k=1,2,…,K$
于是,似然概率为:
即:
其中,$j=1,2,…,n$,$l=1,2,…,S_j$,$k=1,2,…,K$
【贝叶斯估计】
与极大似然估计相似,对于贝叶斯估计,设 $\lambda\geq0$,则对于类先验概率 $P(Y=c_k)$,有:
进一步,假设第 $j$ 个特征 $x^{(j)}$ 可能取值的集合为 $\{a^{(j)}_1,a^{(j)}_2,…,a^{(j)}_{S_j}\}$,其中,$a^{(j)}_l$ 代表第 $j$ 个特征可能取的第 $l$ 个值,$S_j$ 代表第 $j$ 个特征可取值的数量,那么有:
其中,$j=1,2,…,n$,$l=1,2,…,S_j$,$k=1,2,…,K$
可以发现,贝叶斯估计等价于在随机变量各个取值的频数上赋予一个正数 $\lambda\geq0$,而当 $\lambda=0$ 时,即为极大似然估计
一般来说,常取 $\lambda=1$,此时称为拉普拉斯平滑(Laplace smoothing)
那么,对于任意的 $l$ 和 $k$,有:
【实例】
问题描述
现给出一个身高为 高,体重为 中,鞋码为 中 的数据,根据下图中的数据,判断这个数据是男是女

问题分析
设特征:身高为 高 为 $A_1$,体重为 中 为 $A_2$,鞋码为 中 为 $A_3$,类别:男 $C_1$,女 $C_2$
首先要求在 $A_1,A_2,A_3$ 下 $C_k$ 的概率,即:
由于类别仅有两种,因此仅需计算 $P(C_1|A_1A_2A_3)$ 和 $P(C_2|A_1A_2A_3)$,然后输出较大的概率所对应的分类
根据朴素贝叶斯模型:
这就等价于求 $P(A_1A_2A_3|C_k)P(C_k)$ 的最大值
极大似然估计
假设 $A_i$ 之间是相互独立的,那么有:
对于先验概率 $P(Y=c_k)$,其极大似然估计为:
根据数据集,可得:
对于似然概率 $P(X^{(j)}=a_{jl}|Y=c_k)$ ,其极大似然估计为:
根据数据集,可得:
因此,由朴素贝叶斯模型:
可得:
综上,对于给定身高为 高,体重为 中,鞋码为 中 的数据,应是 $C_1$ 类别,为男性
贝叶斯估计
假设 $A_i$ 之间是相互独立的,那么有:
对于先验概率 $P(Y=c_k)$,其贝叶斯估计为:
根据数据集,可得:
对于似然概率 $P(X^{(j)}=a^{(j)}_l|Y=c_k)$ ,其贝叶斯估计为:
根据数据集,可得:
因此,由朴素贝叶斯模型:
可得:
综上,对于给定身高为 高,体重为 中,鞋码为 中 的数据,应是 $C_1$ 类别,为男性
【sklearn 实现】
概述
sklearn 中提供了若干朴素贝叶斯的实现算法,对于不同的朴素贝叶斯实现,主要是对 $P(X^{(j)}=x^{(j)}|Y=c_k)$ 的分布假设不同,以采用不同的参数估计方式
对于朴素贝叶斯来说,其主要就是计算似然概率 $P(X^{(j)}=x^{(j)}|Y=c_k)$,一旦似然概率确定,最终所属每个类别的概率自然也就轻易得出
常用的两种朴素贝叶斯为:
- 高斯朴素贝叶斯:
GaussianNB() - 伯努利朴素贝叶斯:
BernoulliNB()
高斯朴素贝叶斯
高斯朴素贝叶斯适用于连续型随机变量,其假设各特征 $x^{(j)}$ 在各类别 $c_k$ 下服从正态分布,因此算法内部使用正态分布的概率密度函数来计算概率,即:
其中,参数含义如下:
- $\mu_{c_k}$:在类别 $c_k$ 的样本中,特征 $x^{(j)}$ 的均值
- $\sigma_{c_k}$:在类别 $c_k$ 的样本中,特征 $x^{(j)}$ 的标准差
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现高斯朴素贝叶斯
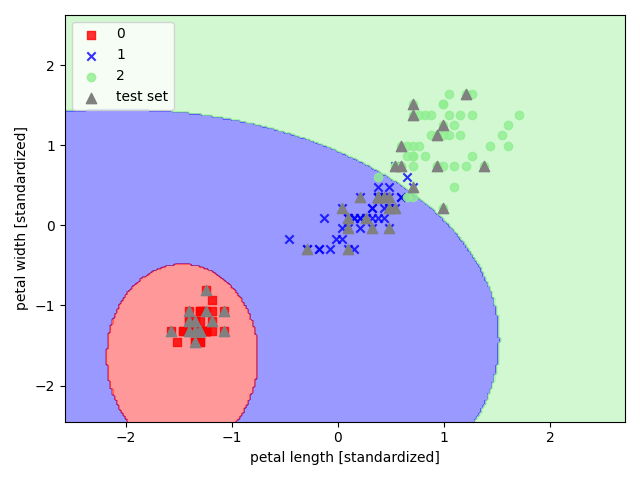
1 | import pandas as pd |
伯努利朴素贝叶斯
伯努利朴素贝叶斯适用于离散型随机变量,其假设各特征 $x^{(j)}$ 在各类别 $c_k$ 下服从 n 重伯努利分布,因此算法内部会首先对特征值 $x^{(j)}$ 进行二值化处理,之后依照如下公式进行概率计算:
在训练集中,会进行如下估计:
其中,参数含义如下:
- $N_{c_k}^{(j)}$:第 $j$ 个特征中属于类别 $c_k$,且特征值为 $1$ 的样本个数
- $N_{c_k}$:属于类别 $c_k$ 的样本个数
- $\alpha$:平滑系数
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现伯努利朴素贝叶斯
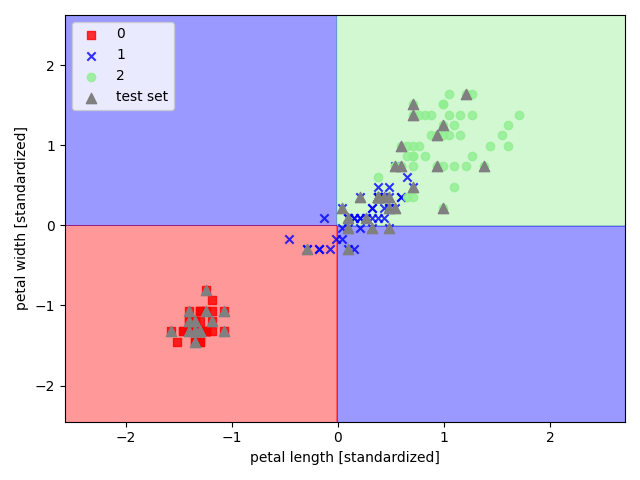
1 | import pandas as pd |

