【假设形式】 在回归分析中,只有一个自变量和因变量,且因变量和自变量之间是线性关系,一般称为一元线性回归(Unary Linear Regression)
通过线性回归算法,会得到很多的线性回归模型,但是不同的模型对于数据的拟合(描述能力) 是不一样的,我们的目的是找到一个能够最精确描述数据之间关系的线性回归模型
其假设形式如下:
对于给定的容量为 $n$ 的样本集 $D=\{(x_1,y_1),(x_2,y_2),…,(x_n,y_n)\}$,第 $i$ 组样本中的输入为 $x_i$,输出为 $y_i$
假设一元线性回归学习到的模型是 $f(x_i;\theta_0,\theta_1)=\theta_0+\theta_1 x_i$,使得 $f(x_i;\theta_0,\theta_1)\simeq y_i$
若要使预测更为精确,那么预测就要以现有的数据为根基,尽量的贴合现有数据,使得预测值与真实值的差距尽量小
这就需要一个损失函数 $J(\theta_0,\theta_1)$ 来作为衡量预测结果的指标,对于损失函数最小化时的 $\theta_0$ 与 $\theta_1$,通常使用最小二乘法 或以梯度下降法 为代表的迭代法来求解
无论使用何种方法,最终的目标,都是要令这个损失函数的值最小化,即
【梯度下降法求解】 对于给定的容量为 $n$ 的样本集 $D=\{(x_1,y_1),(x_2,y_2),…,(x_n,y_n)\}$,第 $i$ 组样本中的输入为 $x_i$,输出为 $y_i$
设习得的模型的假设函数为:
令损失函数为:
之所以要乘以 $\frac{1}{2}$,是因为在求导后会带来 $\times 2$,不利于表达与计算,当乘以 $\frac{1}{2}$ 后,求导带来的 $\times 2$ 就与 $\frac{1}{2}$ 抵消,从而简化计算
目标是通过最小化代价函数 $J(\theta_0,\theta_1)$ 来在参数空间 $\Theta$ 中找到合适的 $\theta_0,\theta_1$ 参数,即:
在最小化代价函数 $J(\theta_0,\theta_1)$ 时,其核心是损失函数对应的梯度函数,使用梯度下降法,即将下列公式重复直到收敛 为止:
即:
关于批量梯度下降法的具体介绍,详见:梯度下降法
【最小二乘法求解】 当使用最小二乘法来求解时,一般选用残差平方和 RSS 作为损失函数,即:
目标是通过最小化代价函数 $J(\theta_0,\theta_1)$ 来在参数空间 $\Theta$ 中找到合适的 $\theta_0,\theta_1$ 参数,即:
在最小化代价函数 $J(\theta_0,\theta_1)$ 时,其核心是损失函数对应的梯度函数,分别对 $J(\theta_0,\theta_1)$ 分别对 $\theta_0$、$\theta_1$ 进行求导,有:
取 $\overline{x}=\frac{1}{n}\sum_\limits{i=1}^nx_i$,$\overline{y}=\frac{1}{n}\sum_\limits{i=1}^ny_i$
令 $\frac{\partial J(\theta_0,\theta_1)}{\partial \theta_0}=0$,$\frac{\partial J(\theta_0,\theta_1)}{\partial \theta_1}=0$,联立后可解得 $\theta_0$ 和 $\theta_1$ 的解析解(Analytical Solution) :
关于普通最小二乘法的具体介绍,详见:最小二乘法
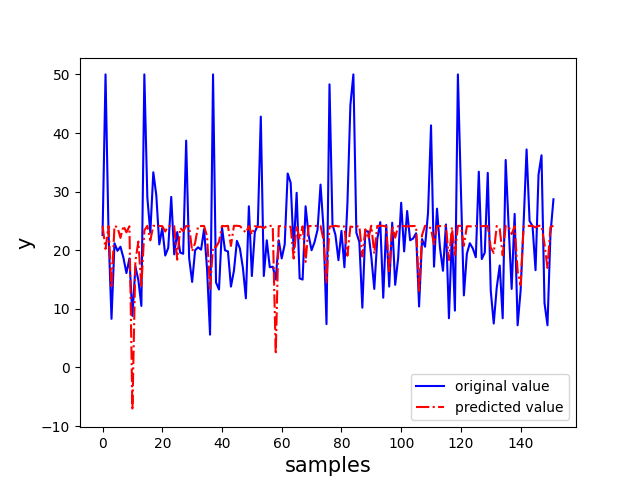
【sklearn 实现】 以 sklearn 中的波士顿房价数据集为例,选取该数据集中的 CRIM 特征作为自变量,选用普通最小二乘法实现一元线性回归
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltfrom sklearn.datasets import load_bostonfrom sklearn.model_selection import train_test_splitfrom sklearn.linear_model import LinearRegressionfrom sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_squared_errorfrom sklearn.metrics import mean_absolute_errorfrom sklearn.metrics import r2_scoredef deal_data (): boston = load_boston() df = pd.DataFrame(boston.data, columns=boston.feature_names) df['result' ] = boston.target data = np.array(df) return data[:, 0 ], data[:, -1 ] def train_model (features, labels ): features = features.reshape(-1 ,1 ) labels = labels.reshape(-1 ,1 ) model = LinearRegression() model.fit(features, labels) return model def estimate_model (y_true, y_pred ): MSE = mean_squared_error(y_true, y_pred) RMSE = np.sqrt(MSE) MAE = mean_absolute_error(y_true, y_pred) R2 = r2_score(y_true, y_pred) indicators = {"MSE" : MSE, "RMSE" :RMSE, "MAE" :MAE, "R2" :R2} return indicators def visualization (y_true, y_pred, model ): plt.plot(range (y_true.shape[0 ]), y_true, "b-" ) plt.plot(range (y_true.shape[0 ]), y_pred, "r-." ) plt.legend(["original value" , "predicted value" ]) plt.xlabel("samples" , fontsize="15" ) plt.ylabel("y" , fontsize="15" ) plt.show() if __name__ == "__main__" : x, y = deal_data() x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3 , random_state=0 ) model = train_model(x_train, y_train) x_test = x_test.reshape(-1 ,1 ) y_pred = model.predict(x_test) y_pred = y_pred.flatten() print ("y test:" , y_test[:10 ]) print ("y pred:" , y_pred[:10 ]) indicators = estimate_model(y_test, y_pred) print ("MSE:" , indicators["MSE" ]) print ("RMSE:" , indicators["RMSE" ]) print ("MAE:" , indicators["MAE" ]) print ("R2:" , indicators["R2" ]) visualization(y_test, y_pred, model)