References:
【概述】
GoogLeNet 是 2014 年 ImageNet 比赛的冠军,与 VGG 是该年 ImageNet 的双雄,这两类模型结构有一个共同特点,即加深网络深度
跟 VGG 不同的是,GoogLeNet 在网络结构做了更大胆的尝试,而不是像 VGG 那样继承了 LeNet-5 以及 AlexNet 的结构
GoogLeNet 模型虽然有 $22$ 层,但其参数数量却比 AlexNet 和 VGG 都小了很多,同时性能更加优越
【Hebbian 原理与稀疏连接】
在深度学习的图像领域,获得高质量模型最保险的方法就是增加网络的深度或宽度,但这种设计思路会导致三个问题:
- 更深的网络会令网络更新的参数爆炸式增长,使得网络更容易发生过拟合,尤其是数据集不足的时候,因此需要为网络提供大量的数据,但样本集的制作是一件复杂的事
- 网络越深更新参数越难,即梯度越向后越容易消失,难以优化模型
- 网络越大计算复杂度越大,需要大量的计算资源,即使当下硬件发展迅速,但这样庞大的计算也是十分昂贵的
解决以上问题的根本方法是将全连接层变为稀疏连接(卷积层实质上就是一个稀疏连接),当某个数据集的分布可以用一个稀疏网络表达的时候,就可以通过分析某些激活值的相关性,将相关度高的神经元进行聚合,从而获得一个稀疏表示
这种方法与生物学中的 Hebbian 原理相对应,即:如果两个神经元经常同时产生动作电位,那么这两个神经元之间的连接就会变强,反之则变弱
举例来说,先摇铃铛,然后给狗喂食,久而久之,狗听到铃铛就会口水连连,狗的听到铃铛的神经元与控制流口水的神经元之间的链接被加强了
【贡献】
受 Hebbian 原则与 NIN 中提出的 $1\times1$ 卷积核与全局平均池化的启发,Christian Szegedy 设计了 GoogLeNet,这个名字一是因为作者在 Google 工作,二是向 LeNet 致敬,该网络的参数比 AlexNet 少 $12$ 倍,但准确率更高
其主要围绕两个思路建立网络结构:
- 深度:采用 $22$ 层的网络结构,为避免梯度消失问题,运用辅助损失分类器来加速网络收敛
- 宽度:增加了 $3\times3$、$5\times5$ 大小的卷积核,但考虑到将这些卷积核直接引用到特征图上,全连接起来的特征度会很大,为此提出了 Inception 结构,进而取消了全连接层
【网络结构】
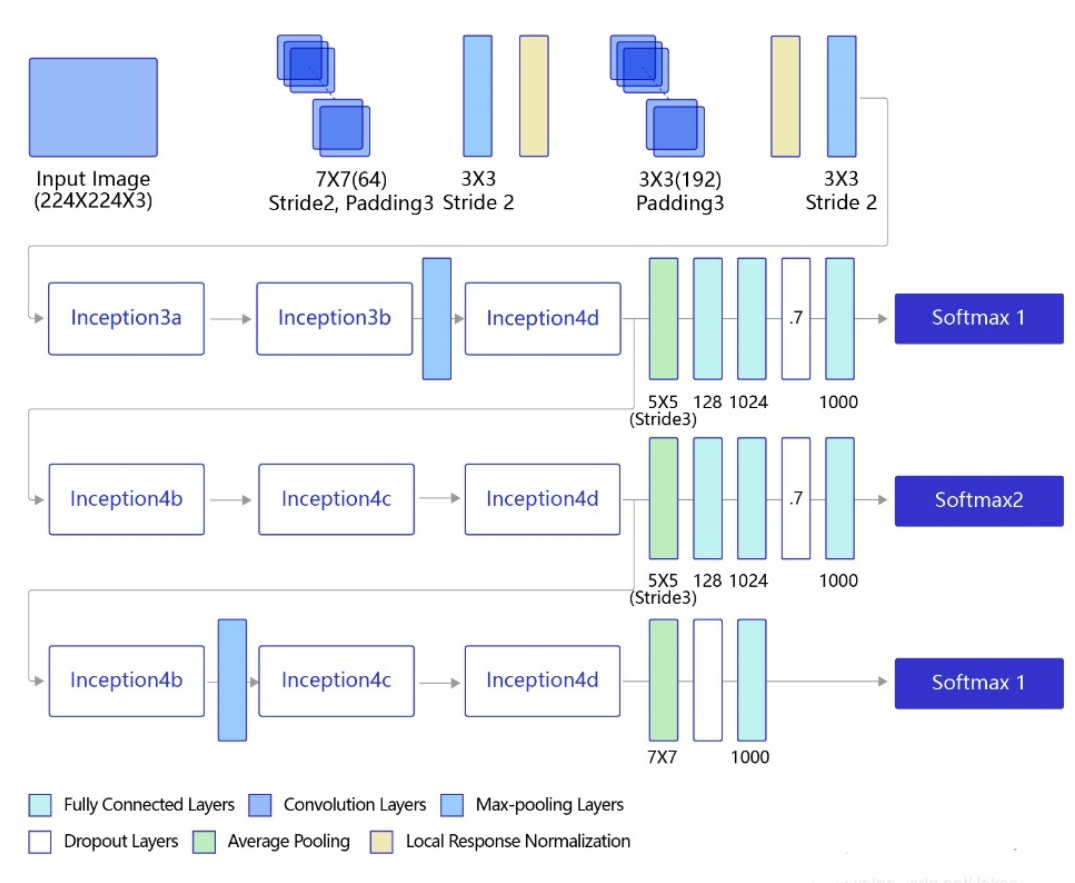
GoogLeNet 的主体卷积部分中使用 $5$ 个模块(block),每个模块之间使用步幅为 $2$ 的 $3\times 3$ 最大池化层来减小输出尺寸,其中:
- 第一个模块使用一个 $64$ 通道的 $7\times 7$ 卷积层
- 第二个模块使用两个卷积层:首先是 $64$ 通道的 $1\times 1$ 卷积层,然后是将通道增大 $3$ 倍的 $3\times 3$ 卷积层
- 第三个模块串联 $2$ 个完整的 Inception 块
- 第四个模块串联了 $5$ 个 Inception 块
- 第五个模块串联了 $2$ 个 Inception 块
- 第五个模块后紧跟输出层,使用全局平均池化层来将每个通道的高和宽变成 $1$,最后接上一个输出个数为标签类别数的全连接层
同时,包括 Inception 模块在内的所有卷积,都用了 ReLU 激活函数,此外,还添加了图中所示的 softmax1 和 softmax2 两个辅助分类器,训练时将三个分类器的损失函数进行加权求和,以缓解梯度消失现象
网络结构如下图所示
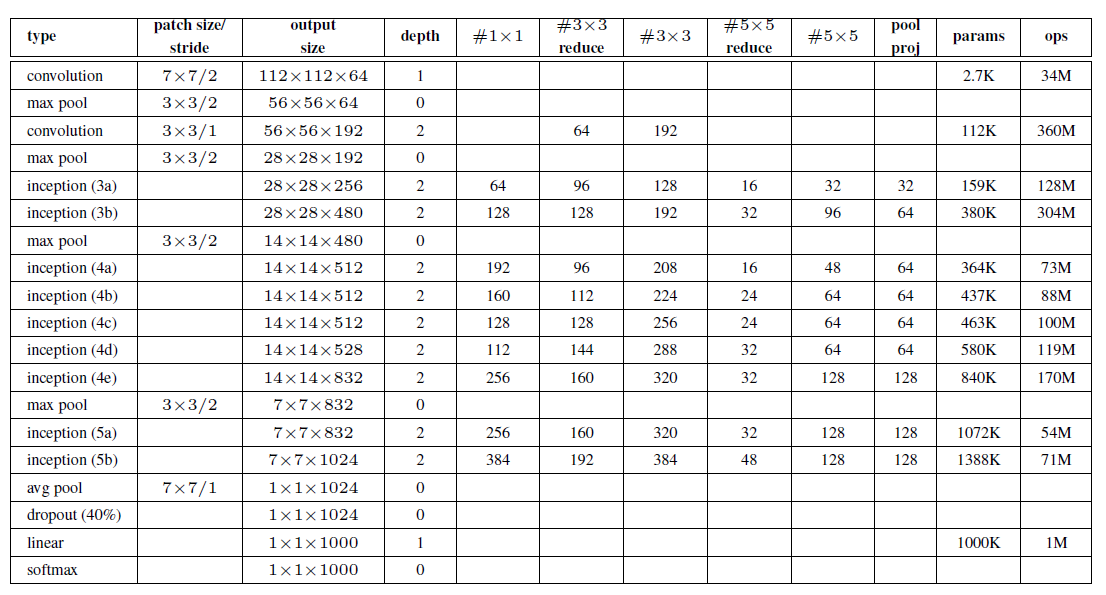
整个网络的参数如下表:
【Inception 结构】
对于提升网络深度和宽度导致的参数爆炸式增长而导致的各种问题,解决的根本方法是将全连接层的结构变为稀疏连接结构,有两种方法:
- 空间上的稀疏连接:只对输入图像的某一部分进行卷积,通过共享参数来降低总参数的数量,即传统 CNN 卷积结构
- 特征维度上的稀疏连接:利用稀疏矩阵分解成密集矩阵计算原理,在特征维度上进行分解,即将相关性强的特征聚集在一起,在多个尺度上的卷积只输出特征的一部分,最后进行聚合
Inception 结构是一种高效表达特征的稀疏性结构,其核心思想就是通过寻找最佳的局部稀疏结构,然后将利用不同尺度的卷积来提取特征,最后进行聚合
这就相当于在特征图的单个局部区域上去学习它的特征,然后在高层用卷积代替这个区域
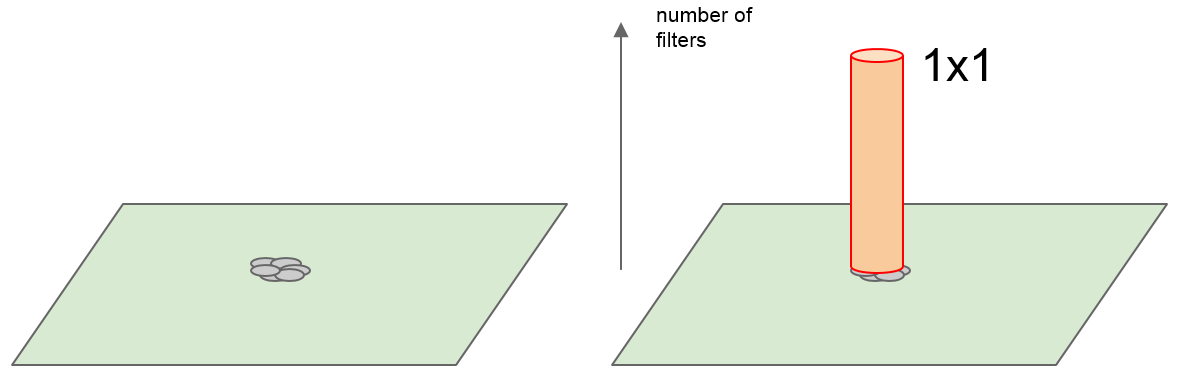
如下图所示,对于特征图上的各特征,相关性强的特征聚集在一起,然后用 $1\times 1$ 的卷积核来学习
考虑到特征图中某些特征的相关性相距较远,因此可以使用较大的 $3\times3$、$5\times5$ 卷积核来学习

进一步,为避免卷积核大小不同带来的区域校准问题,将大小为 $1\times 1$、$3\times3$、$5\times5$ 滤波器进行堆叠
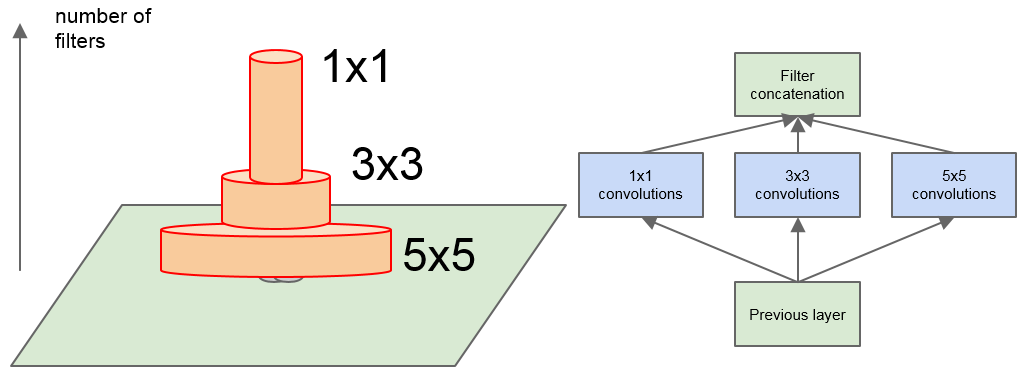
同时,为提高效率,添加一个额外的并行最大池化层,即最简单的 Inception 结构

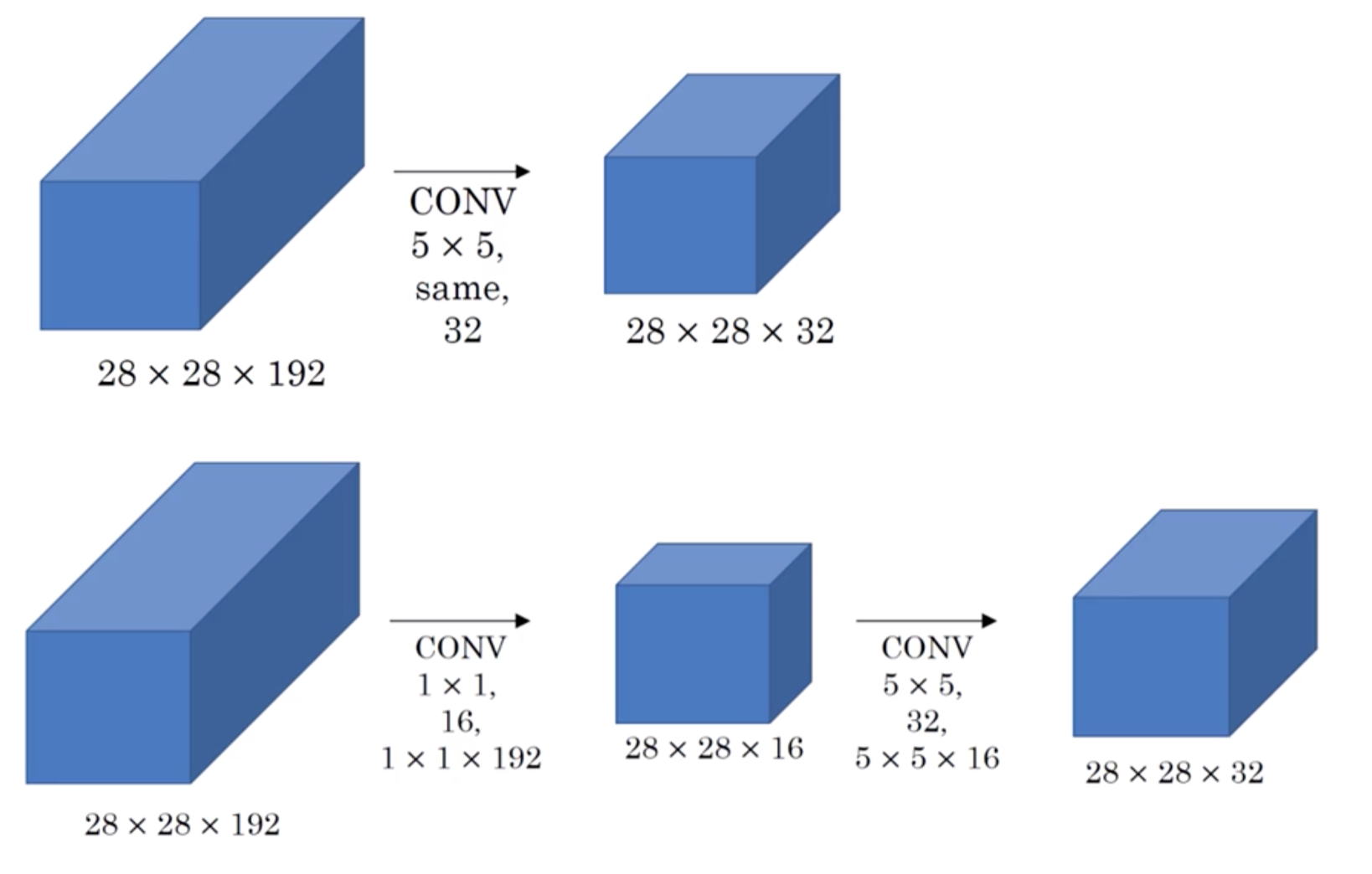
如下图所示,对于输入尺寸为 $28\times28\times 192$ 的图像,使用 Inception 能够得到 $28\times28\times 256$ 大小的特征图,与 AlexNet 中的 $5\times 5$ 卷积作用一致,但使用了更少的参数
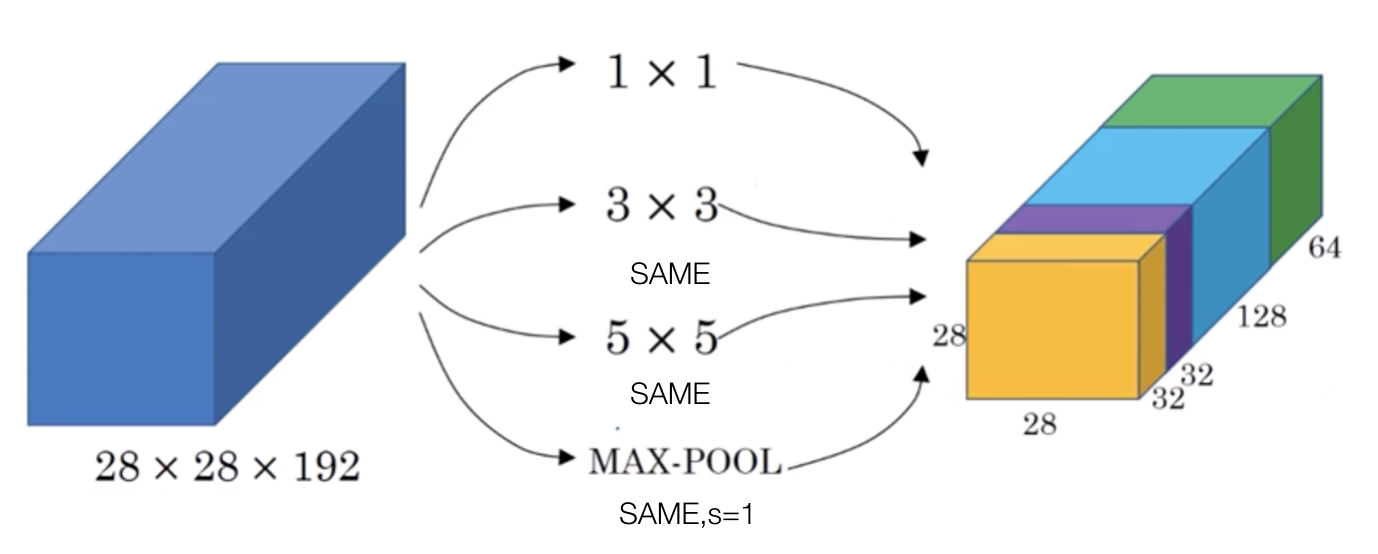
由于 Inception 模块之间是互相堆放的,因此它们的输出相关性统计一定会改变,即:高层次提取高抽象性的特征,空间集中性会降低,故而 $3\times3$ 和 $5\times5$ 的滤波器在更高层会比较多
由于输出滤波器的数量等于前一步中滤波器的数量,卷积层顶端大尺寸滤波器较多,尤其是加入池化单元后,池化层的输出和卷积层的输出融合会导致输出数量逐步增长,这使得计算开销过大,即使这个架构可能包含了最优的稀疏结构, 还是会非常低效,导致计算没经过几步就崩溃
因此有了架构的第二个主要思想:在 $3\times3$、$5\times5$ 的卷积前用一个 $1\times 1$ 卷积进行降维以控制参数量,从而减少计算,同时用于修正线性激活
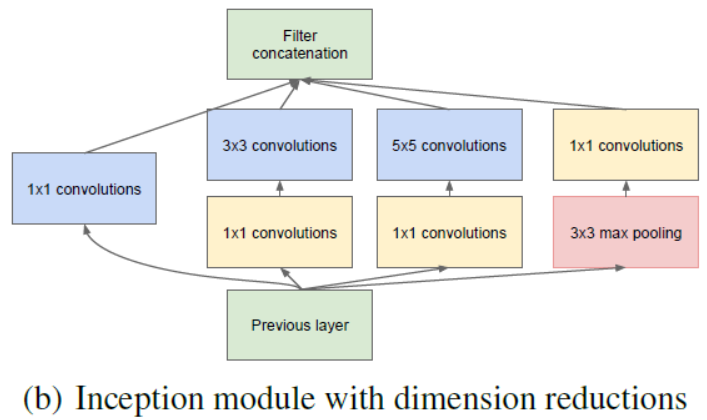
如下图所示,对于输入尺寸为 $28\times28\times 192$ 的图像,在使用 Inception 结构时,对于 $5\times 5\times 32$ 的滤波器部分,其参数个数为 $5 \times 5 \times 32 \times 192 =153,600$,而在其前用 $1\times 1\times16$ 的滤波器进行降维后,参数量为 $192 \times 16 + 5 \times 5 \times 16 \times 32 = 3072 + 12800 = 15872$