【概述】
注意力机制(Attention)是人类大脑的一种天生的能力,当人们看到一幅图片时,先是快速扫过图片,然后锁定需要重点关注的目标区域
例如,当观察下面的图片时,注意力很容易就集中在了人脸、文章标题和文章首句等位置

如果每个局部信息都不放过,那么必然耗费很多精力,同样地,在深度学习网络中引入类似的机制,可以简化模型,加速计算
在深度学习中,注意力机制最早被用于 CNN 模型,在识别图像时,一般是通过卷积核去提取图像的局部信息,然而,每个局部信息对图像能否被正确识别的影响力是不同的,而注意力机制能够让模型知道图像中不同局部信息的重要性
此外,在利用循环神经网络去处理 NLP 任务时,长距离记忆能力一直是个大难题,而引入注意力机制也能有效缓解这一问题,目前流行的 BERT、Transformer 等模型,均基于注意力机制
【基本原理】
架构
Attention 机制的架构可用下图来表示,其与内存中的软寻址(Soft Addressing)十分相似
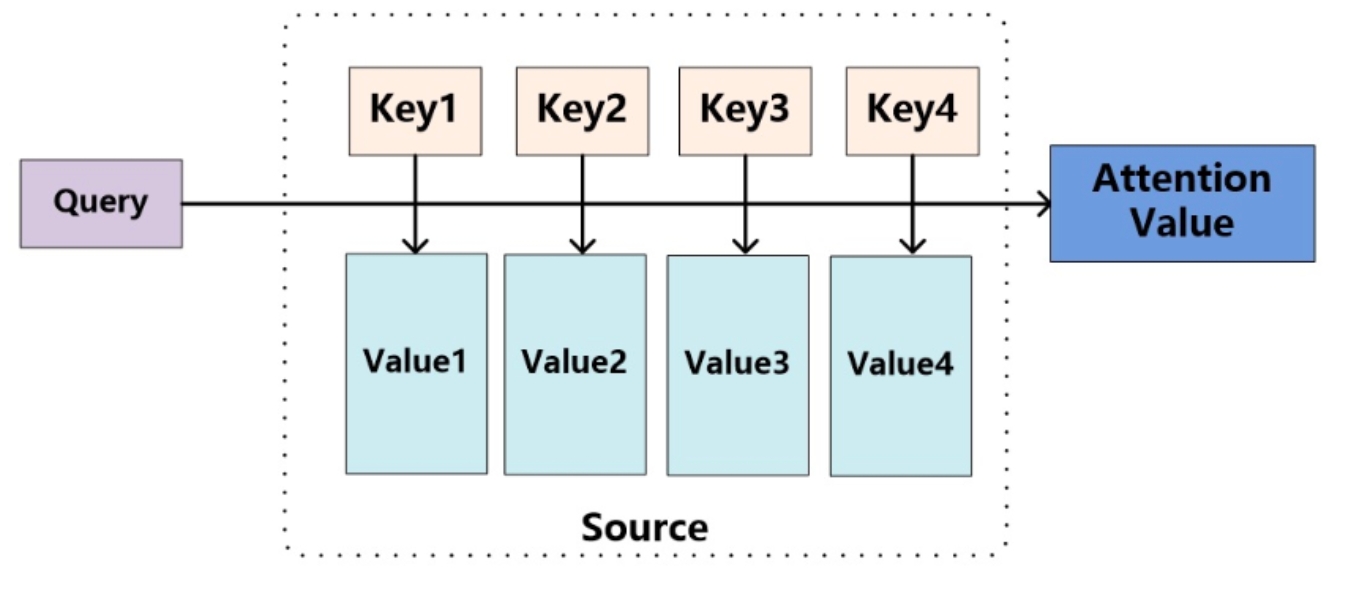
对于软寻址来说,Source 是内存中的一块存储空间,其中存储的数据是由一系列的键值对 $<\text{Key}_i,\text{Value}_i>$ 构成,当给定某个 $\text{Query}$ 时,会取出对应内容
而在 Attention 机制中,当给定某个 $\text{Query}$ 时,会在每个地址中取出一部分内容,然后对所有取出的内容进行加权求和,即计算 $\text{Query}$ 和各个键 $\text{Key}_i$ 的相似性,得到每个键 $\text{Key}_i$ 对应 $\text{Value}_i$ 的权重系数,然后对 $\text{Value}_i$ 进行加权求和,得到最终的 Attention 值
三大阶段
Attention 机制本质上是对 Source 中元素的 $\text{Value}$ 值进行加权求和,而 $\text{Query}$ 和 $\text{Key}$ 用来计算对应 $\text{Value}$ 的权重系数,整个过程可分为如下图的三个阶段:
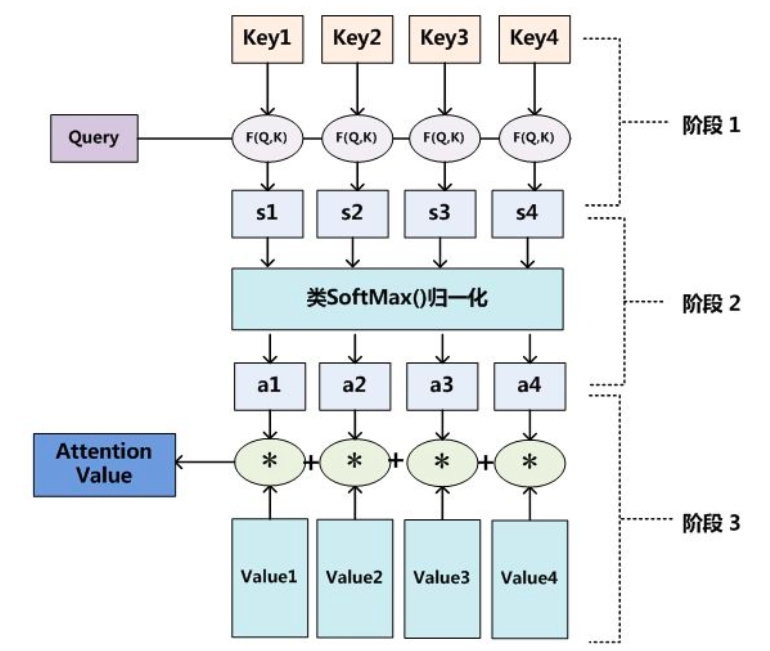
1.计算 $\text{Query}$ 与 Source 中的 $n$ 个 $\text{Key}_i$ 的相似度
2.采用类 Softmax 的方式对相似度进行数值转换,将相似度转为 $[0,1]$ 间的概率分布,即 $\text{Value}_i$ 的权重系数
3.对 $\text{Value}_i$ 的权重系数加权求和
【类型】
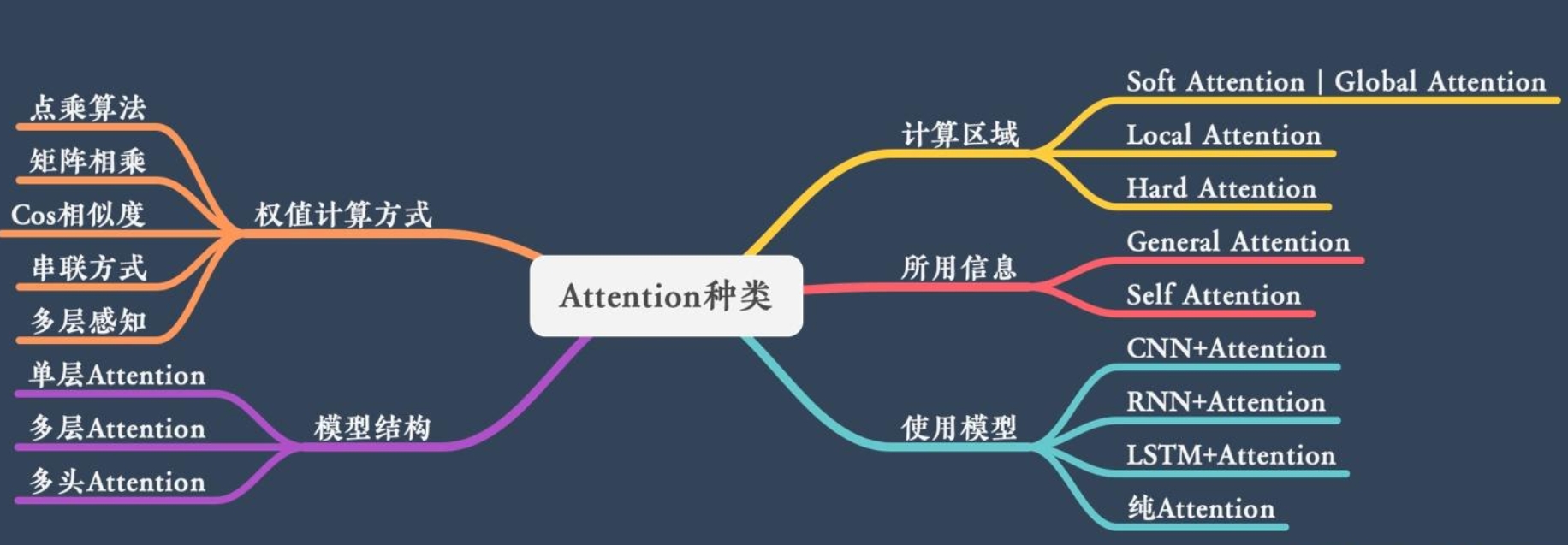
基本分类
随着 Attention 的发展,目前有各种各样的 Attention,从计算区域、所用信息、结构层次和模型结构等方面,可归类为下图
模型结构
根据 Attention 的模型结构,可以分成以下三类:
1)单层注意力机制(Single Attention)
最基础的结构,即每次用一个 $\text{Query}$ 来计算 Attention 值
2)多层注意力机制(Hierarchical Attention)
一般用于文本具有层次关系的模型,每一层都单独使用一个单层 Attention
假设把一个文档划分成多个句子,在第一层,分别对每个句子使用 Attention 计算出一个句向量,在第二层,对所有句向量再次使用 Attention 计算出一个文档向量,最后用这个文档向量去进行下一步任务
3)多头注意力机制(Multi-Head Attention)
将模型分为多个头,形成多个子空间,从而让模型关注不同方面的信息,即利用多个 $\text{Query}$ 进行多次 Attention,每个 $\text{Query}$ 都关注不同部分,相当于重复做多次单层 Attention
最后再将这些结果拼接起来
计算区域
根据 Attention 的计算区域,可以分成以下三类:
1)软注意力机制(Soft Attention)
也称全局注意力机制(Global Attention),即上文中介绍的对所有 $\text{Key}_i$ 求权重概率,再进行加权,但这种方式的计算量可能会较大
2)硬注意力机制(Hard Attention)
直接精准定位到某个 $\text{Key}$,忽略其余的 $\text{Key}$,即相当于定位到的 $\text{Key}$ 的概率是 $1$,其余 $\text{Key}$ 的概率全部是 $0$
这种方式对对齐要求很高,要求一步到位,如果没有正确对齐,则会带来很大的影响,另一方面,因为不可导,一般需要用强化学习的方法进行训练
3)局部注意力机制(Local Attention)
是软注意力和硬注意力的一个折中,其先用 Hard 的方式定位到某个点,然后以这个点为中心得到一个窗口区域,再在这个窗口区域内采用 Soft 的方式来计算 Attention 值
所用信息
假设要对一段文本进行 Attention,那么所用信息包括内部信息和外部信息,内部信息指的是原文本身的信息,而外部信息指的是除原文以外的额外信息
根据 Attention 的所用信息,可以分成以下两类:
1)普通注意力(General Attention)
这种方式利用了内部信息和外部信息,常用于需要构建两段文本关系的任务
一般在 $\text{Query}$ 中包含外部信息,需要根据外部信息对原文进行对齐
例如在阅读理解任务中,需要构建问题和文章的关联,假设要对某问题计算出一个问题向量,然后把这个问题向量和所有的文章词向量拼接起来,输入到 LSTM 中进行建模
那么,在这个模型中,文章所有词向量共享同一个问题向量,现在想让文章每一步的词向量都有一个不同的问题向量,即在每一步使用文章在该步下的词向量对问题来计算 Attention 值,这里问题属于原文,文章词向量就属于外部信息
2)自注意力机制(Self Attention)
这种方式只使用内部信息,即 $\text{Key}$ 和 $\text{Value}$ 以及 $\text{Query}$ 只和输入原文有关
由于没有外部信息,那么在原文中的每个词可以跟该句子中的所有词进行 Attention 计算,相当于寻找原文内部的关系
同样以阅读理解任务为例,假设要对某问题计算出一个问题向量,那么可以直接使用问题自身的信息去做 Attention,而不引入文章信息

