【概述】
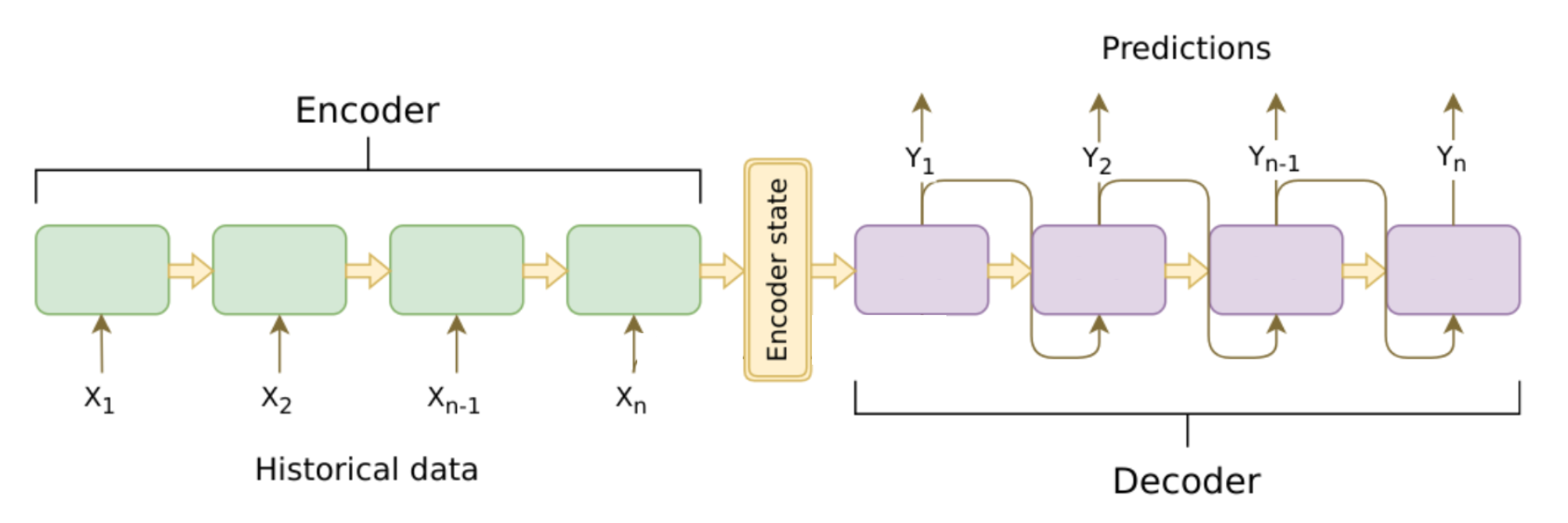
序列到序列(Sequence to Sequence,Seq2Seq)模型,是一种根据给定的序列,通过特定的生成方法生成另一个序列的方法,其是 RNN 的一个变种,解决了 RNN 要求序列等长的问题,其常用于机器翻译、聊天机器人、文本摘要生成等领域中
其属于编码-解码(Encoder-Decoder)结构的一种,编码器 Encoder 和解码器 Encoder 中的每一个 Cell 都是一个 RNN,Encoder 通过学习,将输入序列 $x_1,x_2,\cdots,x_n$ 编码成一个固定大小的状态向量 $C$ 作为解码器的输入,Decoder 则是对这个固定大小的状态向量 $C$ 进行学习,将其解码为可变长度的目标序列进行输出
【训练原理】
对于普通 RNN 的训练,简单来说就是学习概率分布,然后进行预测,比如输入前 $t$ 个时刻的数据,然后预测 $t+1$ 时刻的数据,最后在输出层使用 Softmax 函数进行处理,就得到每个分类的概率,然后选择概率最大的作为预测结果
简单来说,对于训练样本 $x_1,x_2,\cdots,x_t$,其计算的概率是当 $x_1,x_2,\cdots,x_{t-1}$ 成立时,$x_t$ 成立的概率,即整个序列的概率为:
而对于具有两个 RNN 的 Encoder-Decoder 结构,其输入是一个序列,输出也是一个序列,其计算的概率是在输入序列成立的前提下,输出序列成立的概率,即整个序列的概率为:
然后求概率最大的输出序列,作为结果即可
【基础结构】
对于最基础的 Seq2Seq 模型,编码器 Encoder 和解码器 Decoder 中各自只有一个 RNN 单元,Encoder 负责将输入的文本序列编码压缩成指定长度的语义向量 $C$,Decoder 则根据语义向量 $C$ 解码生成指定的序列
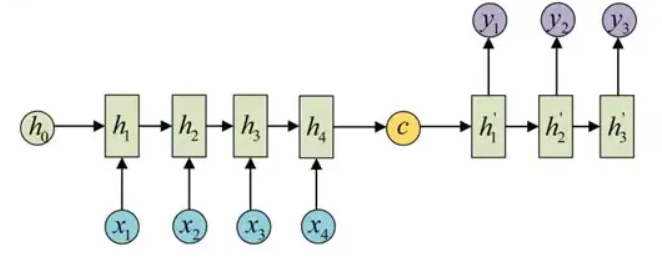
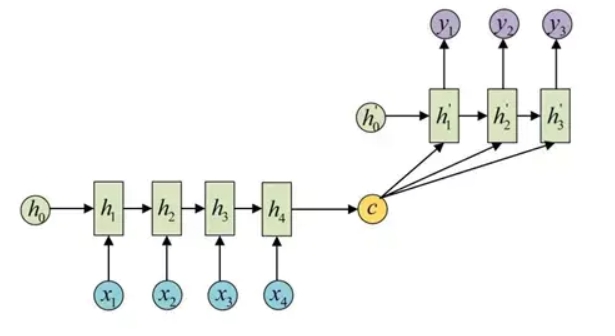
而语义向量 $C$ 输入到解码器 Decoder 中进行训练的方式有两种:
1.将语义向量 $C$ 作为 Decoder 的初始状态 $h_0$ 进行解码运算
2.令语义向量 $C$ 参与到 Decoder 解码运算的每一个过程
【数据流动】
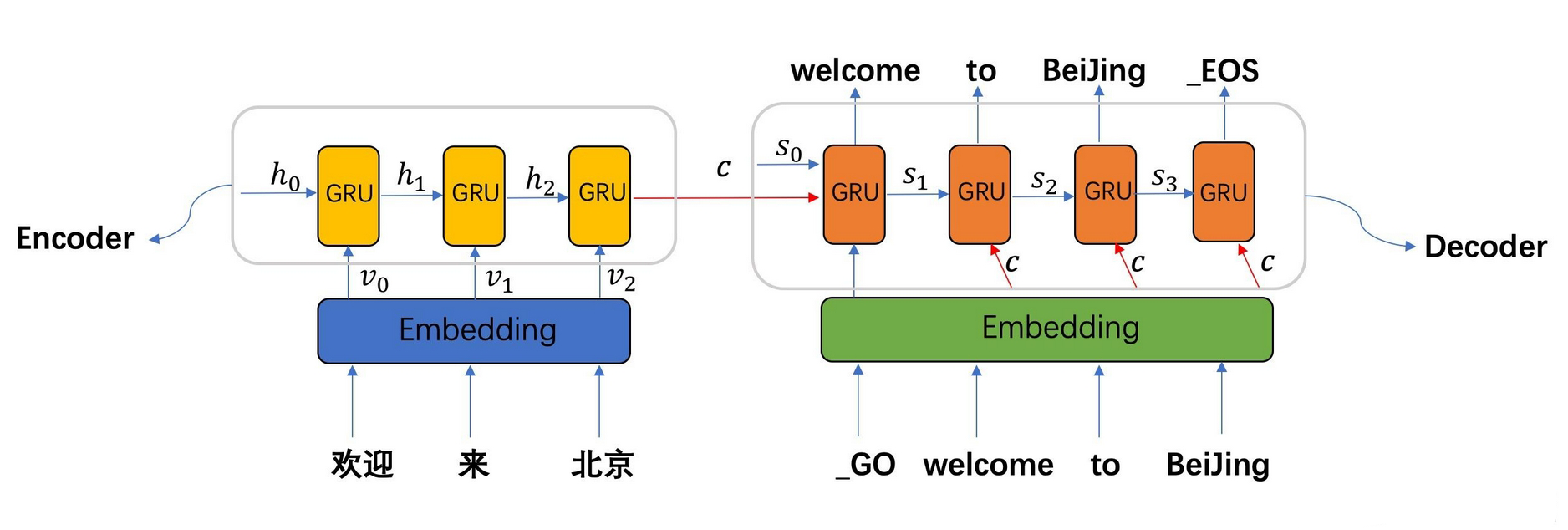
Encoder
如下图所示,Encoder 的数据流动为:
Step1:进行 Embedding,将给定的输入 欢迎/来/北京 转为词向量 $v_0,v_1,v_2$
Step2:将词向量与上一时刻 $i-1$ 的隐状态 $h_{i-1}$ 按照时间顺序进行输入,每一时刻 $i$ 输入一个隐状态 $h_i$,若用函数 $f$ 来表达 RNN 隐藏层的变换,则有
Step3:通过 Encoder 自定义的函数 $q$,将各时刻的隐状态 $h_i$ 转变为语义向量 $c$,假设有 $t$ 个单词,则有
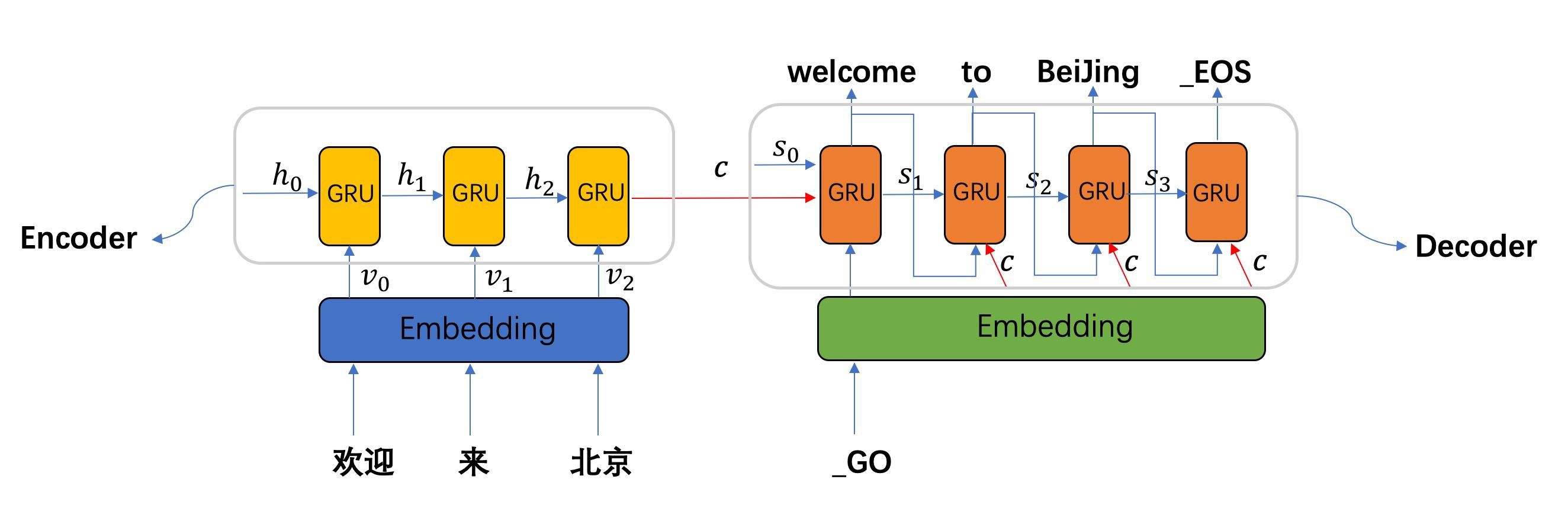
Decoder
训练方式
对于 Seq2Seq 模型来说,Decoder 的训练方式有两种:
- Free Running 方式:后一个 RNN 单元的输入,使用前一个 RNN 单元预测的单词的词向量的 $E_{i-1}$
- Teacher Forcing 方式:后一个 RNN 单元的输入,不使用前一个 RNN 单元预测的单词的词向量的 $E_{i-1}$
对于 Free Running 方式来说,其会造成错误累计,即如果其中一个 RNN 单元解码出现误差,那么这个误差就会传递到下一个 RNN 单元,使训练结果误差越来越大
对于 Teacher Forcing 方式来说,其一定程度上能够缓解错误累计,但由于需要使用要解码的序列作为输入进行训练,因此只能在训练过程中使用该方式来加速模型收敛,无法在推理阶段使用
Free Running 方式
Free Running 方式中,使用前一个 RNN 单元预测的单词的词向量的 $E_{i-1}$,即将语义向量 $c$ 、Decoder 上一时刻 $i-1$ 的隐状态 $s_{i-1}$、前一时刻预测的单词的词向量 $E_{i-1}$ 作为每一时刻的输入,直到解码出 _EOS 时,标志解码结束
若用函数 $g$ 来表达 RNN 隐藏层的变换,则有
需要注意的是,如果是预测第一个词的话,$E_{i-1}$ 为 _GO 的词向量,标志解码的开始
Teacher Forcing 方式
Teacher Forcing 方式中,不使用前一个 RNN 单元预测的单词的词向量的 $E_{i-1}$,即将语义向量 $c$ 、Decoder 上一时刻 $i-1$ 的隐状态 $s_{i-1}$ 作为每一时刻的输入,直到解码出 _EOS 时,标志解码结束
若用函数 $g’$ 来表达 RNN 隐藏层的变换,则有
【集束搜索】
在推理阶段,无法使用 Teacher Forcing 方式,只能使用 Free Running 方式将上一时刻解码的输出作为下一个解码的输入,但这样会导致误差累计
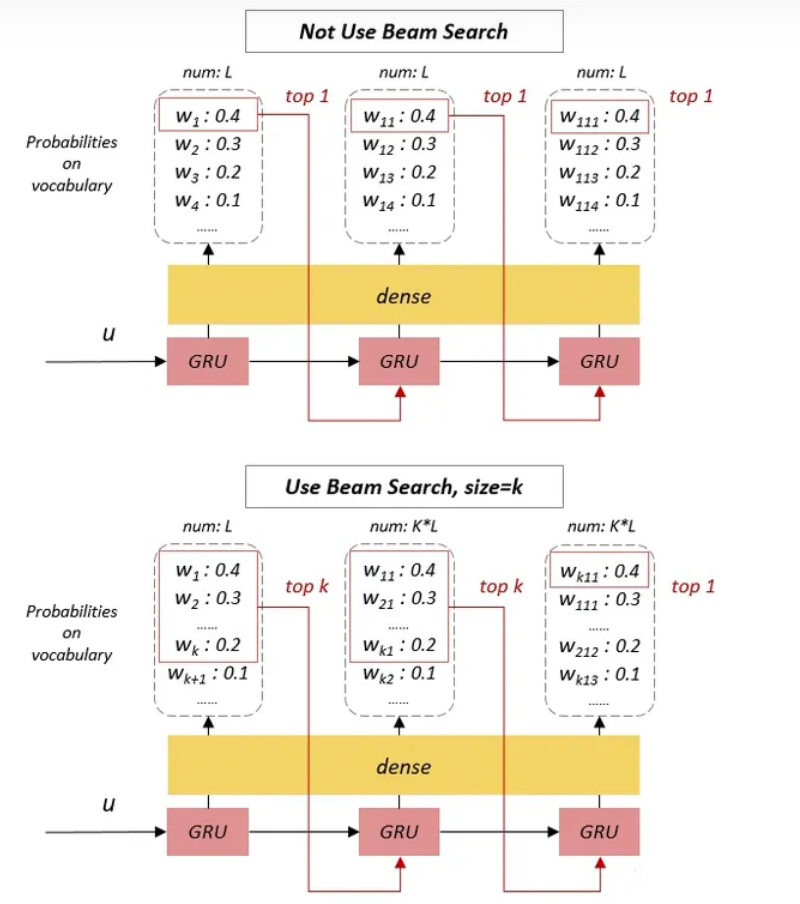
为解决这个问题,一种方式是集束搜索(Beam Search),即在每一时刻的 RNN 单元中执行启发式搜索,生成多个候选作为下一个 RNN 单元的输入
具体来说,在每个时刻的 RNN 单元都会选择 Top-K 个预测结果来作为下一个 RNN 单元的输入,然后将这 $k$ 个结果逐一进行解码,就会产生 $k$ 倍个预测结果,再从所有的解码结果中再选出 Top-K 个预测结果作为下一个 RNN 单元的输入,以此类推,直到在最后一个时刻选出概率最高的作为最终的输出
【Attention 的引入】
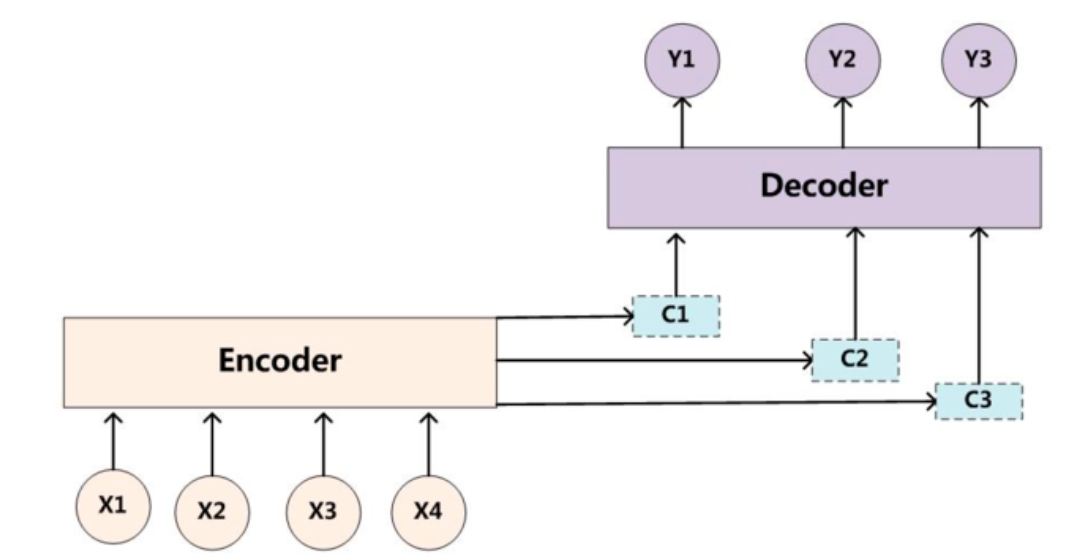
在 Seq2Seq 模型中引入 Attention 机制,也能够使性能有一定的提升
如下图所示,可以发现其具有多个语义编码 $C_1,C_2,C_3$,当预测 $Y_1$ 时,可能注意力是在 $C_1$ 上,那么就用 $C_1$ 作为语义编码,当预测 $Y_2$ 时,可能注意力是在 $C_2$ 上,那么就用 $C_2$ 作为语义编码,以此类推
可以发现,核心就是计算语义向量 $c_1,c_2,\cdots$,假设编码器 Encoder 每个隐藏状态为 $h_j$,序列长度为T,那么在第 $i$ 个时刻语义向量 $c_i$ 向量的计算方式如下 :
其中,$a_{ij}$ 为权重,即在 $j=1,2,…,T$ 时刻的一个概率分布,即有:
其中,$s_{i-1}$ 为解码器 Decoder 在 $i-1$ 时刻的隐状态

