【概述】
由于顺序队列中的假溢出会造成极大的空间浪费,为避免这种浪费,对可采用以下两种方法来克服:
- 将队列中所有元素均向低地址区移动
- 将存储队列的数组头尾相接,当存放到 $n$ 地址后,下一个地址就翻转为 $1$
对于第一种方法来说,由于每个元素都需要向前移动空间,这无疑十分浪费时间,为此,常采用第二种方法,采用循环队列
循环队列,就是将顺序队列从逻辑上视为一个环,从而克服假溢出问题
循环队列的实现类如下:
1 |
|
【初始化】
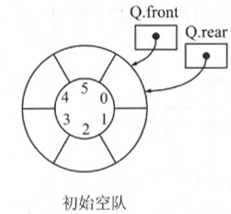
初始时,队列为空队列,此时队头指针 head 与队尾指针 tail 均设为 $0$
1 | template <typename T> |
【求队长】
由于队首与队尾在逻辑上相连,因此在求队长时,要将两者的差值加上存储空间长度后再取存储空间的模,即 (tail + N - head) % N
1 | template <typename T> |
【判空】
由于 tail 指向队尾元素的下一位置,即接下来要插入的位置,因此在判空时,只需判断队尾指针与队头指针是否相同即可
1 | template <typename T> |
【判满】
在判满时,考虑到队首与队尾在逻辑上相连的因素,当队首指针与队尾指针加一后取存储空间的模相等,说明队满,即 (tail + 1) % N == head
1 | template <typename T> |
【出队】
在出队时,取队首指针 head 指向的元素,之后令队首指针后移一位,同时,考虑到队首与队尾在逻辑上相连的因素,要对队首指针取对存储空间 N 的模,即 head = (head + 1) % N
1 | template <typename T> |
【入队】
在入队时,将元素存入队尾指针 tail 指向的位置,之后令队尾指针后移一位,同时,考虑到队首与队尾在逻辑上相连的因素,要对队尾指针取对存储空间 N 的模,即 tail = (tail + 1) % N
1 | template <typename T> |
【取队首】
在取队首元素时,先进行下溢判断,然后直接取队首指针 head 指向的元素即可
1 | template <typename T> |
【输出】
在输出时,从队首开始,将队列中所有元素依次出队,进行输出即可
1 | template <typename T> |
【关于队空与队满】
为区分队空与队满,有三种处理方式:
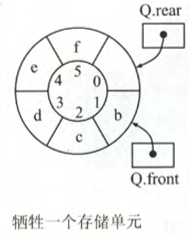
方式一约定队首指针 head 在队尾指针 tail 的下一位置为队满标志,这样通过牺牲一个存储单元即可识别队空、队满,即开辟的存储空间为 $N$ 时,最大队长为 $N-1$,此时有:
- 队空条件:
head == tail - 队满条件:
(tail + 1) % N == head - 队长:
(tail + N - head) % N
在存储结构中增设一个整型数据成员 size,用于标识元素个数,每次入队成功就令 size++,出队成功就令 size--,此时有:
- 队空条件:
size == 0 - 队满条件:
size == N - 队长:
size
由于在不牺牲存储空间时,无法确定 head == tail 时是队空开始队满
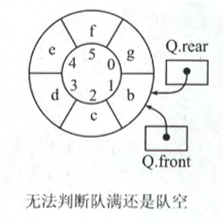
因此可以在存储类型中增设一布尔类型数据成员 tag,用于标识最近进行的是入队还是出队操作,每次入队成功令 tag=true,出队成功令 tag=false,此时有:
- 队空条件:由于只有出队才会导致队空,故
!tag && head == tail - 队满条件:由于只有入队才会导致队满,故
tag && head == tail - 队长:
(tail + N - head) % N

