【局部性原理】
程序访问的局部性原理包括时间局部性和空间局部性:
- 时间局部性:在最近的未来要用到的信息,很可能是现在正在使用的信息,这是因为程序存在循环
- 空间局部性:在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是邻近的,这是因为指令通常是顺序存放、顺序执行的,数据一般也是以向量、数组、表等形式簇聚地存储在一起的
高速缓冲技术就是利用程序访问的局部性原理,把程序中正在使用的部分存放在一个高速的、容量较小的 Cache 中,使 CPU 的访存操作大多数针对 Cache 进行,从而使程序的执行速度大大提高
【Cache 工作原理】
结构
Cache 位于存储器层次结构的顶层,通常由 SRAM 构成

Cache 和主存都被分成若干大小相等的块(Cache 块又称为 Cache 行),每块由若干字节组成,块的长度称为块长(Cache 行长)
由于 Cache 的容量远小于主存的容量,所以 Cache 中的块数要远少于主存中的块数,它仅保存主存中最活跃的若干块的副本,故而 Cache 会按照某种策略,预测 CPU 在未来一段时间内欲访存的数据,将其装入 Cache
读请求
当 CPU 发出读请求时,如果访存地址在 Cache 中命中,就将此地址转换成 Cache 地址,直接对 Cache 进行读操作,与主存无关;如果 Cache 不命中,则仍需访问主存,并把此字所在的块一次从主存调入 Cache 内
若将块从主存调入 Cache 时,Cache 已满,则需根据某种替换算法,用这个块替换掉 Cache 中原来的某块信息
需要注意的是,CPU 与 Cache 之间的数据交换以字为单位,而 Cache 与主存之间的数据交换则是以 Cache 块为单位
此外,在某些计算机中也采用同时访问 Cache 和主存的方式,若 Cache 命中,则主存访问终止,否则访问主存并替换 Cache
写请求
当 CPU 发出写请求时,如果 Cache 命中,有可能会遇到 Cache 与主存中的内容不一致的问题
例如:由于 CPU 写 Cache,把 Cache 某单元中的内容从 $X$ 修改成了 $X’$,而主存对应单元中的内容仍然是 $X$,没有改变
所以如果 Cache 命中,需要按照一定的写策略处理,即:全写法、写回法
而如果 Cache 未命中,也会按照一定的写策略处理,即:写分配法、非写分配法
【Cache 性能指标】
CPU 欲访问的信息已在 Cache 中的比率称为 Cache 的命中率
设一个程序执行期间,Cache 的总命中次数为 $N_c$,访问主存的总次数为 $N_m$,则命中率 $H$ 为:
可见为提高访问效率,命中率 $H$ 越接近 $1$ 越好
设 $t_c$ 为命中时的 Cache 访问时间,$t_m$ 为未命中时的访问时间,$1-H$ 表示未命中率,则 Cache-主存系统的平均访问时间 $T$ 为:
【Cache 地址映射】
原理
在 Cache 中,地址映射是指把主存地址空间映射到 Cache 地址空间,也就是把存放在主存中的程序按照某种规则装入 Cache 中
由于 Cache 块数比主存块数少得多,这样主存中只有一部分块的内容可放在 Cache 中,因此在 Cache 中要为每一块加一个标记,指明它是主存中哪一块的副本,该标记的内容相当于主存中块的编号
为了说明标记是否有效,每个标记至少还应设置一个有效位,该位为 $1$ 时,表示 Cache 映射的主存块数据有效,否则无效
需要注意的是,地址映射不同于地址变换,地址变换是指 CPU 在访存时,将主存地址按映射规则换算成 Cache 地址的过程
直接映射
主存数据块只能装入 Cache 中的唯一位置,若这个位置已有内容,则产生块冲突,原来的块将无条件地被替换出去(无需使用替换算法)
直接映射实现简单,但不够灵活,即使 Cache 存储器的其他许多地址空着也不能占用,这使得直接映射的块冲突概率最高,空间利用率最低
直接映射的关系可定义为:
其中,$j$ 是 Cache 的块号,$i$ 是主存的块号,$2^c$ 是 Cache 中的总块数
在这种映射方式中,主存的第 $0$ 块、第 $2^c$ 块、第 $2^{c+1}$ 块、$….$,只能映射到 Cache 的第 $0$ 行,而主存的第 $1$ 块、第 $2^{c+1}$块、$2^{c+1}+1$ 块、$…$,只能映射到 Cache 的第 $1$ 行,依次类推
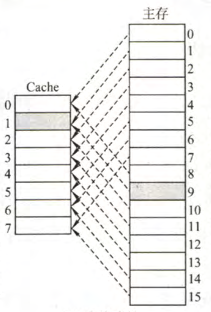
直接映射的地址结构如下图

全相联映射
全相联映射可以把主存数据块装入 Cache 中的任何位置
全相联映射方式的优点是比较灵活,Cache 块的冲突概率低,空间利用率高,命中率也高,缺点是地址变换速度慢,实现成本高,通常需采用昂贵的按内容寻址的相联存储器进行地址映射
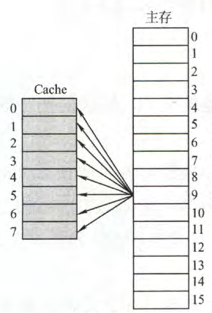
全相联映射的地址结构如下图

组相联映射
组相联映射将 Cache 空间分成大小相同的组,主存的一个数据块可以装入到一组内的任何一个位置,即组间采取直接映射,而组内采取全相联映射,它是对直接映射和全相联映射的一种折中
组相联映射的关系可以定义为:
其中,$j$ 缓存的组号,$i$ 是主存的块号,$Q$ 是 Cache 的组数,当 $Q=1$ 时变为全相联映射,当 $Q$ 为 Cache 块数时变为直接映射
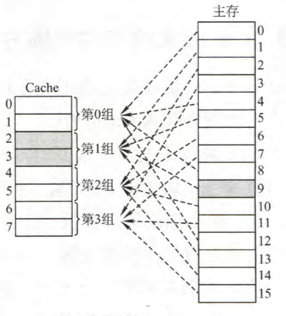
组相联映射的地址结构如下图所示

【Cache 替换算法】
在采用直接映射时,一个给定的主存块只能放到一个唯一的固定 Cache 行中,所以,在对应 Cache 行已有一个主存块的情况下,新的主存块毫无选择地把原先已有的那个主存块替换掉,无需考虑替换算法
而在采用全相联映射和组相联映射方式时,从主存向 Cache 传送一个新块,当 Cache 中的空间已被占满时,就需要使用替换算法置换 Cache 行
常用的替换算法有以下几种:
- 随机算法 RAND:随机地确定替换的 Cache 块,实现简单,但没有依据程序访问的局部性原理,故可能命中率较低
- 先进先出算法 FIFO:选择最早调入的行进行替换,实现简单,但也没有依据程序访问的局部性原理,可能会把一些需要经常使用的程序块(如循环程序)也作为最早进入 Cache 的块替换掉
- 近期最少使用算法 LRU:依据程序访问的局部性原理选择近期内长久未访问过的存储行作为替换的行,该算法对每行设置一个计数器,Cache 每命中一次,命中行计数器清 $0$,其他各行计数器均 $+1$,需要替换时比较各特定行的计数值,将计数值最大的行换出
- 最不经常使用算法 LFU:将一段时间内被访问次数最少的存储行换出,每行也设置一个计数器,新行建立后从 $0$ 开始计数,每访问一次,被访问的行计数器 $+1$,需要替换时比较各特定行的计数值,将计数值最小的行换出
【Cache 写策略】
因为 Cache 中的内容是主存块副本,当对 Cache 中的内容进行更新时,就需选用写操作策略使 Cache 内容和主存内容保持一致
Cache 写命中
全写法
全写法是指当 CPU 对 Cache 写命中时,必须把数据同时写入 Cache 和主存,当某一块需要替换时,不必把这一块写回主存,将新调入的块直接覆盖即可
这种方法实现简单,能随时保持主存数据的正确性。缺点是增加了访存次数,降低了 Cache 的效率
此外,为减少全写法直接写入主存的时间损耗,会在 Cache 和主存之间加一个写缓冲,CPU 同时写数据到 Cache 和写缓冲中,写缓冲再控制将内容写入主存
写缓冲是一个 FIFO 队列,可以解决速度不匹配的问题,但如果出现频繁写时,会使写缓冲饱和溢出
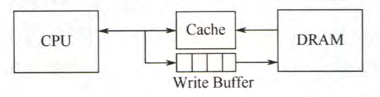
写回法
写回法是指当 CPU 对 Cache 写命中时,只修改 Cache 的内容,而不立即写入主存,只有当此块被换出时才写回主存
这种方法减少了访存次数,但存在不一致的隐患,采用这种策略时,每个 Cache 行必须设置一个标志位(脏位),以反映此块是否被CPU修改过
Cache 写不命中
写分配法
写分配法是指当 CPU 对 Cache 写不命中时,加载主存中的块到 Cache 中,然后更新这个 Cache 块
写分配法试图利用程序的空间局部性,但是每次不命中都需要从主存中读取一块,效率较低
写分配法通常会与写回法配合使用
非写分配法
非写分配法是指当 CPU 对 Cache 写不命中时,只写入主存,不进行调块
非写分配法通常会与全写法配合使用
【多级 Cache】
现代计算机的 Cache 通常设立多级 Cache(通常为 $3$ 级),假定设 $3$ 级 Cache,按离 CPU 远近可各自命名 L1 Cache、L2 Cache、L3 Cache,离 CPU 越远,访问速度越慢,容量越大
指令 Cache 与数据 Cache 分离一般在 L1 级别,此时通常为写分配法与写回法合用
如下图,是一个含有两级 Cache 的系统,L1 Cache 对 L2 Cache 使用全写法,L2 Cache 对主存使用写回法,由于 L2 Cache 的存在,其访问速度大于主存,这样避免了因频繁写时造成的写缓冲饱和和溢出


