Reference
【概述】
坐标下降法(Coordinate Descent)是一种非梯度优化算法,常用于不可微的凸函数优化问题中
与梯度下降法利用目标函数的导数来确定搜索方向不同,坐标轴下降法是每次沿着单个维度方向进行搜索,当得到一个当前维度最小值之后再循环使用不同的维度方向,最终收敛得到最优解
对于每次进行的最小值的搜索,其实就是把其他的变量看作常量,然后目标凸函数 $f(\cdot)$ 就看作是关于当前搜索变量的函数,在该函数上进行线性搜索,每次迭代时某个维度的搜索会使用上一维度搜索的结果
例如,对于函数 $f(x,y)=xe^{-(x^2+y^2)}$,当对其进行坐标下降的搜索结果如下图所示
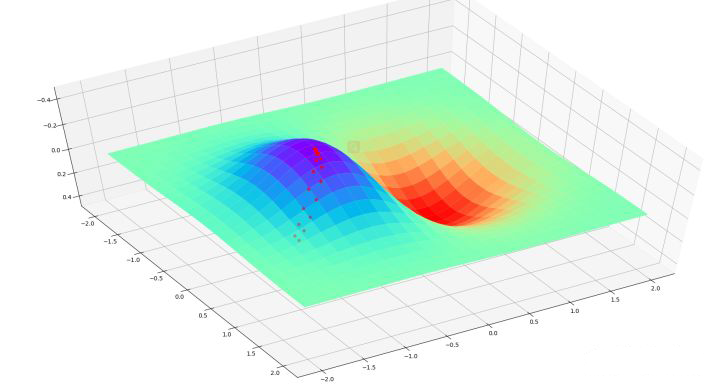
图中的红色小点就是搜索过程,可以看到红点是交替分布的,这印证了坐标下降法分别在不同维度上进行交替搜索的过程
坐标下降法与梯度下降法的不同之处在于,坐标下降法不需要计算目标函数的梯度,每次迭代只用在单一维度上进行线性搜索,但是坐标下降法只适用于光滑函数,如果是非光滑函数可能会陷入非驻点从而无法更新
【基本思想】
对于无约束极小化问题:
其中,$f(\cdot)$ 为目标优化凸函数,$\mathbf{x}=(x^{(1)},x^{(2)},…,x^{(n)})^T\in \mathbb{R}^n$,$x^{(i)}$ 为向量 $\mathbf{x}$ 的第 $i$ 个分量
坐标下降法的基本过程如下:
首先,选取 $x^{(2)},x^{(3)},…,x^{(n)}$ 的初值
然后,进行迭代,在每轮迭代中进行如下操作
固定 $x^{(2)},x^{(3)},…,x^{(n)}$,将 $x^{(1)}$ 作为自变量,进行线性搜索,得到:
将得到的 $(x^{(1)})^*$ 代入凸函数,同时固定 $x^{(3)},x^{(4)},…,x^{(n)}$,搜索得到:
将得到的 $(x^{(1)})^*,(x^{(2)})^*$ 代入凸函数,同时固定 $x^{(4)},x^{(5)},…,x^{(n)}$,搜索得到:
以此类推,最终得到本轮迭代后的一组值:
若结果收敛或满足迭代终止条件,则达到最优值,否则进行下一轮迭代
其迭代过程可以表示为:
其中,$x_k^{(i)}$ 代表第 $k$ 次迭代时的第 $i$ 个系数
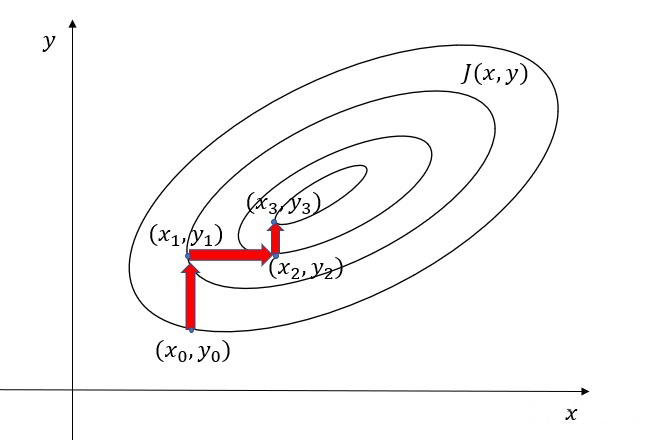
以二维空间为例,设损失函数 $J(x,y)$ 为凸函数,在初始点固定 $x_0$,使得 $J(x_0,y)$ 达到最小的 $y_1$,然后固定 $y_1$,使得 $J(x,y_1)$ 达到最小的 $x_2$,如此迭代下去,由于 $J(x,y)$ 为凸函数,所以一定可以找到使得 $J(x,y)$ 达到最小的点 $(x_k,y_k)$
【全局最小值】
可微凸函数
假设坐标下降法收敛后的坐标点为 $\mathbf{x}$,函数上的任意一点为 $\mathbf{y}$,根据多元函数的二阶泰勒展开,有:
对于可微的凸函数,坐标下降法的收敛处各坐标方向的偏导必为 $0$,即:$\triangledown f(\mathbf{x})=0$
否则函数沿着坐标轴方向必存在函数值进一步下降的空间,这与坐标下降法的迭代终止条件相违背
此外,可微凸函数的海森矩阵为正定矩阵,即:$\triangledown^2 f(\mathbf{x})=0$
故而可得:
因此,对于可微凸函数,坐标下降法的任意局部最优解即为全局最优解
不可微凸函数
对于不可微凸函数,很容易举出坐标下降法不适用的例子
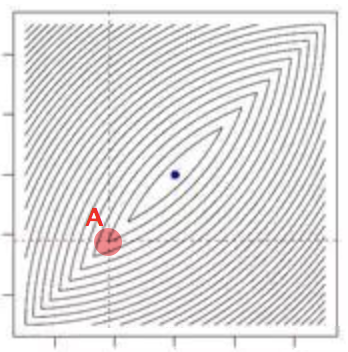
如下等高线图,蓝色点处为全局最小值点,若以红色点 A 为初始点进行坐标下降法,由于沿着平面内两根轴都无法进一步下降,所以最终值仍为红色点 A ,此时坐标下降法失效
联合函数凸函数
假设目标函数为可微凸函数 $f(\mathbf{x})$ 和不可微凸函数 $h(\mathbf{x})$ 的和,且 $h(\mathbf{x})$ 可写为各坐标轴方向的和:
假设坐标下降法收敛后的坐标点为 $\mathbf{x}$,函数上的任意一点为 $\mathbf{y}$,则有:
因此,对于可微凸函数和不可微凸函数的联合函数,坐标下降法的最终结果即为全局最小值点

