【引入】
在 单层感知机 中,介绍了单层感知机模型:
其可以处理线性可分的二分类问题
与(AND)、或(OR)、非(NOT)均可认为是一线性可分问题,即这三种逻辑电路均可使用单层感知机来实现
而对于异或(XOR)来说,其是一个线性不可分问题,无法使用单层感知机来实现,考虑到异或可以通过与、或、非来组合实现:
那么,借鉴这种思想,将多个感知机进行连接,形成层级结构,由此有了多层感知机(Muti-Layer Perceptron,MLP)
【从与或非到异或】
与门
与门,是具有两个输入和一个输出的门电路,在两个输入均为 $1$ 时输出 $1$,其他情况输出 $0$
其真值表如下:
| $x_1$ | $x_2$ | $y$ |
|---|---|---|
| $0$ | $0$ | $0$ |
| $0$ | $1$ | $0$ |
| $1$ | $0$ | $0$ |
| $1$ | $1$ | $1$ |
若想使用感知机来表示与门,需要做的就是确定参数 $\omega_1,\omega_2$ 与阈值 $\theta$,使得在给定二值输入时,感知机的输出能够满足真值表
满足真值表条件的参数的选择方案有无数种,这里选取较为简单的一种,即:
此时,有:
仅当 $x_1=x_2=1$ 时,有 $y=1$
其分离超平面如下:
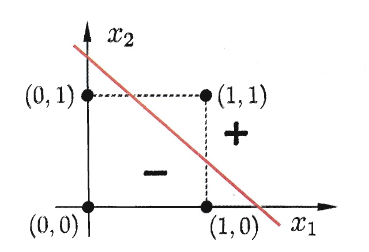
或门
或门,是具有两个输入和一个输出的门电路,在两个输入中的任意一个为 $1$ 时输出 $1$,在两个输入全为 $0$ 时输出 $0$
其真值表如下:
| $x_1$ | $x_2$ | $y$ |
|---|---|---|
| $0$ | $0$ | $0$ |
| $0$ | $1$ | $1$ |
| $1$ | $0$ | $1$ |
| $1$ | $1$ | $1$ |
若想使用感知机来表示或门,需要做的就是确定参数 $\omega_1,\omega_2$ 与阈值 $\theta$,使得在给定二值输入时,感知机的输出能够满足真值表
满足真值表条件的参数的选择方案有无数种,这里选取较为简单的一种,即:
此时,有:
当 $x_1=1$ 或 $x_2=1$ 时,有 $y=1$
其分离超平面如下:

非门
非门,是具有一个输入和一个输出的门电路,在输入为 $1$ 时输出 $0$,输入为 $0$ 时输出 $1$
其真值表如下:
| $x$ | $y$ |
|---|---|
| $0$ | $1$ |
| $1$ | $0$ |
若想使用感知机来表示非门,需要做的就是确定参数 $\omega$ 与阈值 $\theta$,使得在给定输入时,感知机的输出能够满足真值表
满足真值表条件的参数的选择方案有无数种,这里选取较为简单的一种,即:
此时,有:
当 $x=1$ 时,有 $y=0$;当 $x=0$ 时,有 $y=1$
其分离超平面如下:

异或门
异或门,是具有两个输入和一个输出的门电路,在两个输入相同时输出 $0$,在两个输入不同时输出 $1$
其真值表如下:
| $x_1$ | $x_2$ | $y$ |
|---|---|---|
| $0$ | $0$ | $0$ |
| $0$ | $1$ | $1$ |
| $1$ | $0$ | $1$ |
| $1$ | $1$ | $0$ |
其分离超平面如下:
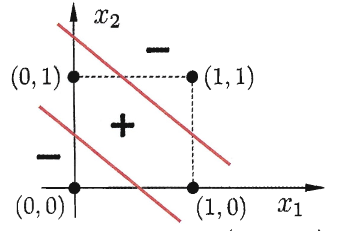
可以看出,若想将其分开,只能通过如下图的曲线来分割
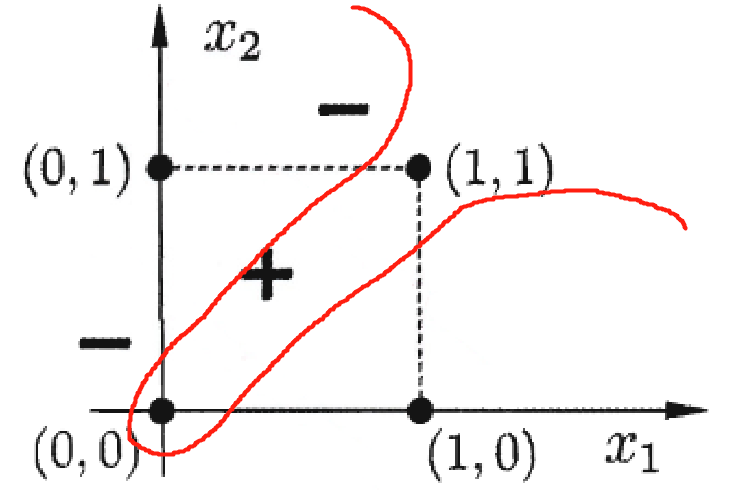
可以发现,异或问题是一个非线性可分问题,单层感知机无法进行实现
在数字电路中,异或门可以通过与门、非门、或门的组合来实现
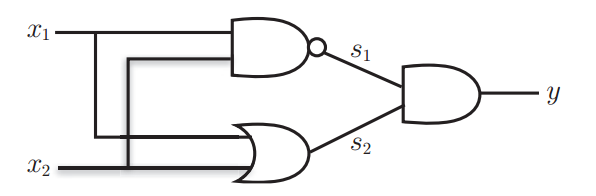
根据上面的数字电路图,给出真值表:
| $x_1$ | $x_2$ | $s_1$ | $s_2$ | $y$ |
|---|---|---|---|---|
| $0$ | $0$ | $1$ | $0$ | $0$ |
| $0$ | $1$ | $1$ | $1$ | $1$ |
| $1$ | $0$ | $1$ | $1$ | $1$ |
| $1$ | $1$ | $0$ | $1$ | $0$ |
那么,参考真值表,可以构建出如下由 MP 神经元构成的网络图,即最简单的多层感知机

其中,第 $0$ 层为输入层(Input Layer),该层不涉及到计算;第 $1$ 层用于处理数据,被称为隐藏层(Hidden Layer),第 $2$ 层为输出层(Output Layer),将隐藏层的输出进行处理,作为整个多层感知机的输出
【多层感知机】
多层感知机(Multi-Layer Perceptron,MLP),也叫人工神经网络(Artificial Neural Network,ANN),是最简单的神经网络结构,其除了输入层和输出层外,中间可以有多个隐藏层,最简单的 MLP 只包含一个隐藏层

如上图所示的多层感知机,每层神经元与下一层神经元完全互连,且神经元间不存在同层连接与跨层连接,这样的神经网络结构被称为多层前馈神经网络(Multi-layer Feedforward Neural Networks)
对于多层前馈神经网络来说,输入层用于接收外接输入,隐藏层与输出层对输入进行处理,并由输出层输出,因此,上图所示的多层感知机,其层数为 $2$,一般称为两层网络
第 $0$ 层为输入层,该层不涉及到计算;第 $1$ 层为隐藏层,含有 $5$ 个 MP 神经元;第 $2$ 层为输出层,含有 $3$ 个 MP 神经元
设第 $1$ 层权重为 $W_h$,阈值为 $\theta_h$,激活函数为 $f(\cdot)$,则该多层感知机隐藏层的输出为:
设第 $2$ 层权重为 $W_o$,阈值为 $\theta_o$,则该多层感知机的输出为:
将上述两个式子联立,可得:
在分类问题中,通常会将输出层的输出单元个数设为 $1$ ,并对输出 $O$ 进行 softmax 运算,将输出转换为分类概率
多层感知机的学习过程,就是根据训练数据来调整神经元间的连接权重以及每个神经元的阈值,除了使用随机梯度下降法、牛顿法等迭代算法外,由于多层感知机是最基础的神经网络,其还可使用 BP 算法训练
关于 BP 算法,详见:BP 神经网络与反向传播算法
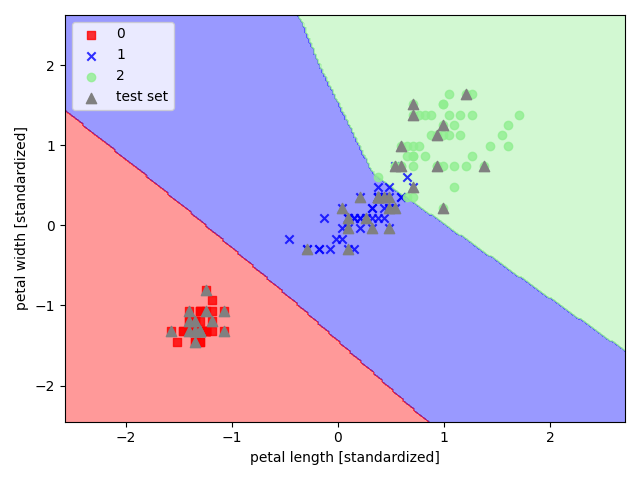
【sklearn 实现】
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现多层感知机
1 | import pandas as pd |

