【概述】
感知机(Perceptron)是神经网络和支持向量机的起源算法,从结构上来讲,其分为单层感知机(Single Layer Perceptron)和多层感知机(Multi-Layer Perceptron)
单层感知机就是 MP 神经元,其一般用于处理线性可分问题,多层感知机是多个 MP 神经元的累叠,通过增加层数来处理线性不可分问题
单层感知机与 MP 神经元最主要的区别,在于感知机引入了损失函数与参数学习的过程,这是为什么将感知机称为最初的神经网络模型的原因
本文仅介绍单层感知机,为便于表述,以下内容所提到的感知机,均为单层感知机
【单层感知机模型】
假设形式
单层感知机是一种二分类的线性分类模型,其本质上是寻找特征空间 $\mathbb{R}^{n}$ 中的一个超平面 $S:\boldsymbol{\omega}\cdot \mathbf{x}+\theta=0$,将特征空间划分为两个部分,使得位于两部分的点被分为正负两类
设输入空间 $\mathcal{X}\in \mathbb{R}^{n}$,输出空间 $\mathcal{Y}=\{-1,+1\}$,输入 $\mathbf{x}=(x^{(1)},x^{(2)},…,x^{(n)})\in\mathcal{X}$ 为实例的特征向量,对应于输入空间的点,输出 $y\in\mathcal{Y}$ 为实例的类别
在感知机中,激活函数一般使用 $\text{sign}(\cdot)$ 函数:
其中,$\boldsymbol{\omega}\in \mathbb{R}^{n}$ 为权值(Weight),$\theta\in \mathbb{R}$ 为阈值(Threshold),$\boldsymbol{\omega}\cdot \mathbf{x}$ 表示 $\boldsymbol{\omega}$ 与 $\mathbf{x}$ 的内积
可以发现,感知机与 MP 神经元本质上是一致的,只是为了便于表达,将阈值 $\theta$ 取负,从而使得 $\boldsymbol{\omega}\cdot\mathbf{x}-\theta$ 的减法变为 $\boldsymbol{\omega}\cdot\mathbf{x}+\theta$ 的加法
损失函数
假设训练集是线性可分的,单层感知机学习的目标是求得一个能够将训练集正样本和负样本完全正确分开的分离超平面,为找出这样的分离超平面,即求得感知机的模型参数 $\boldsymbol{\omega}$ 和阈值 $\theta$,为此,需要定义经验损失函数并将该损失函数极小化
在感知机模型中,最直观的损失函数是误分类样本点的个数,但这样的损失函数不是 $\boldsymbol{\omega}$ 与 $\theta$ 的连续可导函数,不易优化,因此,在感知机中一般选用误分类样本点到超平面 $S$ 的总几何间隔作为损失函数
在 线性可分与几何间隔 中,介绍了对于分离超平面 $S:\boldsymbol{\omega}\cdot \mathbf{x}+\theta=0$ 几何间隔:
对于样本集 $D$ 中的误分类的样本 $(\mathbf{x}_j,y_j)$ 来说,有:
- 当 $\boldsymbol{\omega}\cdot\mathbf{x}_j+\theta>0$ 时,$y_j=-1$
- 当 $\boldsymbol{\omega}\cdot\mathbf{x}_j+\theta<0$ 时,$y_j=+1$
即:
由此,误分类样本 $(\mathbf{x}_j,y_j)$ 到超平面 $S$ 的几何间隔为:
那么,假设超平面 $S$ 的误分类点的集合为 $E$,则所有误分类点到超平面 $S$ 的总几何间隔为:
于是,对于给定训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_N,y_N)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $n$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})\in \mathbb{R}^n$,输出 $y_i\in\mathcal{Y}=\{+1,-1\}$
对于误分类点集 $E=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_M,y_M)\},M\leq N$,第 $j$ 组样本中的输入 $\mathbf{x}_j$ 具有 $n$ 个特征值,即:$\mathbf{x}_j=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})\in \mathbb{R}^n$,输出 $y_j\in\mathcal{Y}=\{+1,-1\}$
不考虑 $\frac{1}{||\boldsymbol{\omega}||_2} $,感知机 $f(\mathbf{x})=\text{sign}(\boldsymbol{\omega}\cdot \mathbf{x}+\theta)$ 的损失函数为:
显然,$L(\boldsymbol{\omega},\theta)$ 是非负的,若没有误分类点,则 $L(\boldsymbol{\omega},\theta)=0$,同时,误分类点越少,误分类点就距离超平面越近,损失函数值也就越小
【sklearn 实现】
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现感知机
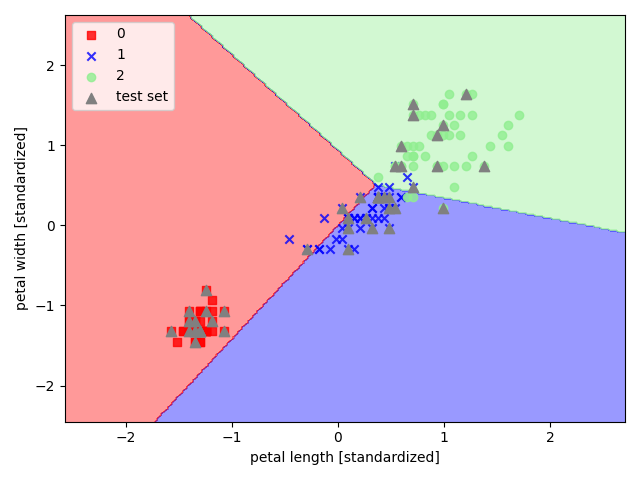
1 | import pandas as pd |

