【概述】
K 近邻(K-Nearest Neighbor,KNN)是常用的监督学习方法之一,既可处理分类问题,也可处理回归问题
一般来说,当利用 KNN 处理分类任务时,通常使用投票法,即选择这 $k$ 个邻居中出现最多的类别标记作为预测结果;当利用 KNN 处理回归任务时,通常使用平均法,即将这 $k$ 个邻居的输出标记的平均值作为预测结果
同时,KNN 是懒惰学习(Lazy Learning)的著名代表,在训练阶段仅仅将样本保存,训练开销时间为 0,待接收到测试样本后再进行处理;相应地,在训练阶段就对样本进行处理的学习方法,称为急切学习(Eager Learning)
KNN 需要计算待测样本和训练集中所有样本的距离,时间复杂度为 $O(n)$,一般适用于样本数较少的数据集,当数据集很大时,不仅耗时,而且需要大量的存储空间,因此当数据量大时,一般将数据以树的形式呈现,以提高速度,常用的方法有:KD-Tree 与 Ball-Tree
其中,KD 树对于低维度($D<20$)的近邻搜索非常快,但当维数 $D$ 增长到很大时,效率会变低,这是维度灾难的一种体现,为解决 KD 树在高维上效率低下的问题,Ball 树应运而生
【算法流程】
虽然 KNN 既可处理分类问题,也可处理回归问题,但一般将其用于处理分类问题
就分类效果来说,KNN 对于随机分布的数据集分类效果较差,对于类内间距小,类间间距大的数据集分类效果好,且对于边界不规则的数据效果好于线性分类器
此外,KNN 对于样本不均衡的数据效果不好,需要进行改进,一般改进的方法是对 $k$ 个近邻数据赋予权重,例如:距离测试样本越近,权重越大
KNN 工作机制十分简单:对于给定的测试样本,基于某种度量找出训练集中与该样本最靠近的 $k$ 个样本,然后基于这 $k$ 个邻居的信息进行预测,其算法流程如下:
对于给定的训练数据集 $T=\{(\mathbf{x_1},y_1),(\mathbf{x_2},y_2),…,(\mathbf{x_n},y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x_i}$ 具有 $m$ 个特征值,即:$\mathbf{x_i} =(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}= \{c_1,c_2,…,c_K\}$ 为实例的类别
当给定一个实例特征向量 $\mathbf{x}$ 时,根据给定的距离度量,KNN 会在训练集 $T$ 中找出与 $\mathbf{x}$ 最近邻的 $k$ 个点,涵盖这 $k$ 个点的 $\mathbf{x}$ 的邻域记作 $N_k(\mathbf{x})$
在 $N_k(\mathbf{x})$ 中根据分类决策规则(如投票法)决定 $\mathbf{x}$ 的类别 $y$:
【距离度量】
在特征空间中,两个实例点的距离是这两个实例点的相似程度的反映
KNN 的特征空间一般是 $m$ 维实数向量空间 $\mathbb{R}^{m}$,常选用闵氏距离作为相似度度量标准
设特征空间 $\mathcal{X}$ 是 $m$ 维实数向量空间 $\mathbb{R}^m$,$\mathbf{x_i},\mathbf{x_j}\in \mathcal{X}$,且 $\mathbf{x_i}$ 和 $\mathbf{x_j}$ 满足 $\mathbf{x_i}=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})^T$,$\mathbf{x_j}=(x_j^{(1)},x_j^{(2)},…,x_j^{(m)})^T$
则 $\mathbb{x_i}$ 与 $\mathbb{x_j}$ 的闵氏距离定义为:
【近邻数 k】
近邻数 k,即在预测目标点时取 $k$ 个临近的点来预测,对于不同的样本,近邻数 $k$ 有着不同的取值,如何确定 $k$ 值获得最佳的结果是十分困难的
- 当 $k$ 的取值过小时,一旦有噪声的成分存在,将会对预测产生比较大影响,容易发生过拟合
- 当 $k$ 的取值过大时,就相当于用较大邻域中的训练实例进行预测,学习的近似误差会增大,这时与输入目标点较远实例也会对预测起作用,使预测发生错误
此外,对于 $k=1$ 的情况,称为最近邻算法,该算法将训练集中与输入实例 $x$ 最近邻点的类视为 $x$ 的类;而当 $k=n$,即取全部的实例时,无论输入的实例是什么,都将简单地预测其属于训练集中最多的类,此时模型过于简单,完全忽略了训练集中的信息,预测没有意义
同时,$k$ 的取值尽量要取奇数,以保证在计算结果最后会产生一个较多的类别,因为取偶数可能会产生相等的情况,不利于预测
在应用中,最常用的方法是从 $k=1$ 开始,使用检验集来估计分类器的误差率,然后不断重复该过程,每次令 $k$ 增加一个近邻,最后选取具有最小误差率的 $k$,一般来说,$k$ 的取值上限是 $\sqrt n$
【分类决策规则】
在 KNN 中,分类决策规则往往是多数表决(Majority Voting Rule),又称投票法,其是由输入实例的 $k$ 个邻近的训练样本中的多数类决定输入实例的类
对于给定的训练数据集 $T=\{(\mathbf{x_1},y_1),(\mathbf{x_2},y_2),…,(\mathbf{x_n},y_n)\}$,输入实例为 $\mathbf{x}$,则 $\mathbf{x}$ 的预测类别 $y$ 为:
若分类的损失函数为 0-1 损失函数,分类函数为:
设正确分类的概率为:
则误分类的概率为:
进一步,对于给定的输入实例 $\mathbf{x}\in\mathcal{X}$,其最近邻的 $k$ 个训练样本点构成集合 $N_k(x)$,若涵盖 $N_k(\mathbf{x})$ 的区域类别为 $c_j$,则正确分类率为:
故误分类率为:
要使误分类率即经验风险最小,就要使 $\sum\limits_{\mathbf{x_i}\in N_k(\mathbf{x})}I(y_i= c_j)$ 最大
因此,可以认为,多数表决规则等价于经验风险最小化
【实例】
假设在二维平面上,有四个点:$a_1(1,1)$、$a_2(1,2)$、$b_1(3,3)$、$b_2(3,4)$,其中,$a_1,a_2$ 属于 $A$ 类,$b1,b2$ 属于 $B$ 类
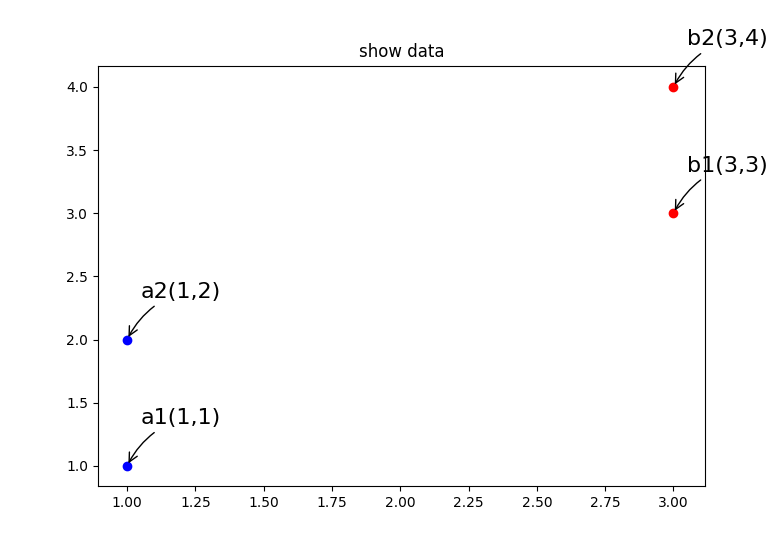
给出一个目标点 $c(2,1)$,现在想要知道对于 $c(2,1)$ 这个点来说,其属于 $A$ 类还是 $B$ 类
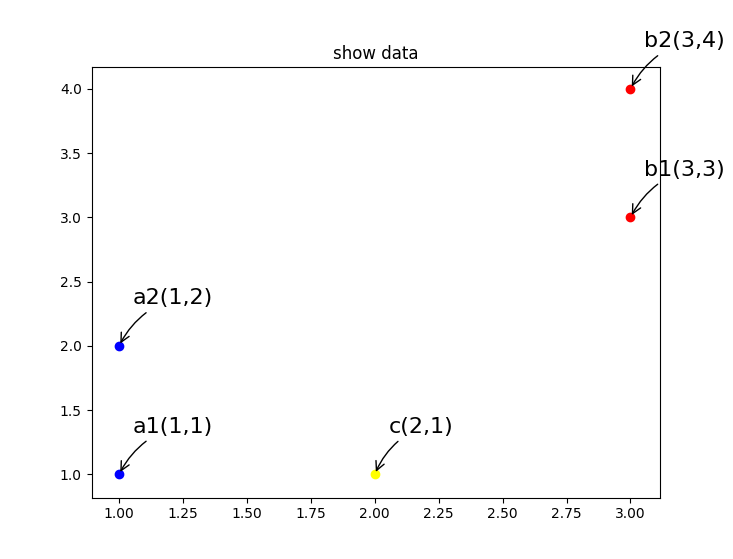
首先计算目标点 $c$ 到其他 $4$ 个点的距离,为方便计算,使用曼哈顿距离:
- $M(a_1,c) = |1-2|+|1-1| = 1$
- $M(a_2,c) = |1-2|+|2-1| = 2$
- $M(b_1,c) = |3-2|+|3-1| = 3$
- $M(b_2,c) = |3-2|+|4-1| = 4$
然后将计算出的距离集合按距离升序排序:
| 序号 | 点 | 类别 | 坐标 | 距离 |
|---|---|---|---|---|
| $1$ | $a_1$ | $A$ | $(1,1)$ | $1$ |
| $2$ | $a_2$ | $A$ | $(1,2)$ | $2$ |
| $3$ | $b_1$ | $B$ | $(3,3)$ | $3$ |
| $4$ | $b_2$ | $B$ | $(3,4)$ | $4$ |
接着取距离列表排序后的前 $k$ 个数据,这里令 $k=3$
| 序号 | 点 | 类别 | 坐标 | 距离 |
|---|---|---|---|---|
| $1$ | $a_1$ | $A$ | $(1,1)$ | $1$ |
| $2$ | $a_2$ | $A$ | $(1,2)$ | $2$ |
| $3$ | $b_1$ | $B$ | $(3,3)$ | $3$ |
最后,统计这 $k$ 个数据里,出现频次最多的类别。
在该样例中,根据上表可以看出,$A$ 出现了两次,$B$ 出现了一次,因此我们认为点 $c$ 属于 $A$ 类
【sklearn 实现】
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现 K 近邻
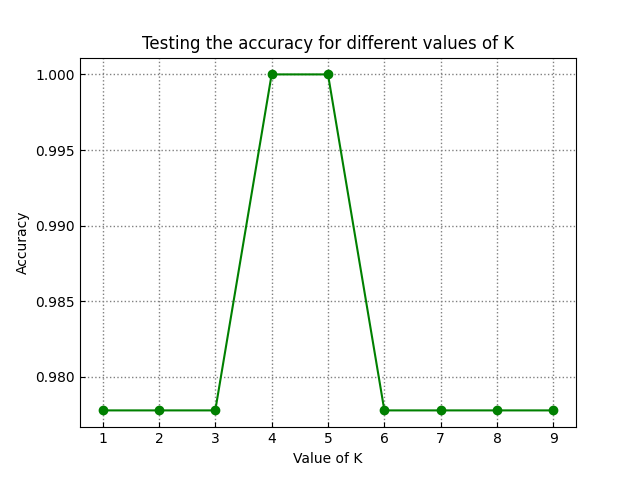
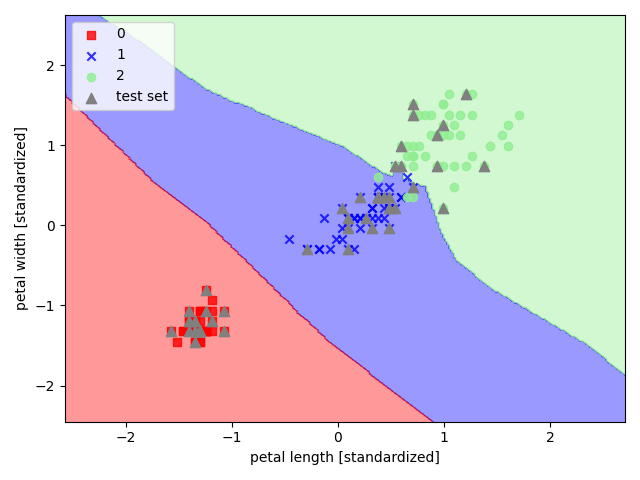
1 | import pandas as pd |

