References:
【引入】
硬间隔支持向量机是用来解决训练集完全线性可分情况的二分类模型,但在实际应用中,由于实际获取的真实样本往往会存在噪声,使得训练数据不是清晰线性可分的,又或者即使找到了一个可以使不同类样本完全分开的超平面,也很难确定这个线性可分的结果是不是由于过拟合导致的
也就是说,训练集中存在一些特异点(Outlier),将这些特异点去除后,剩余大部分的样本点的集合是线性可分的,这被称为近似线性可分
对于近似线性可分的训练集,引入了软间隔(Soft Margin)这个概念,并将求解硬间隔最大化问题改为求解软间隔最大化问题,从而使得硬间隔支持向量机更一般化,能够对近似线性可分的数据进行处理
【假设形式】
对于给定容量为 $n$ 的线性不可分训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_n,y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $m$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}=\{+1,-1\}$
软间隔支持向量机(Soft Margin Support Vector Machines)对于线性不可分的训练集,通过求解软间隔最大化问题:
其中,$\xi_i\geq 0$ 是为每个样本点 $(\mathbf{x}_i,y_i)$ 引入的松弛变量,$C>0$ 是惩罚系数
得到最优分离超平面:
以及相应的分类决策函数:
由于现实中的训练数据往往存在噪声或特异点,是线性不可分的,因此软间隔支持向量机具有更广的适用性
同时,由于软间隔支持向量机是在硬间隔支持向量机基础上针对训练数据线性不可分时的改进,因此又称线性支持向量机(Linear Support Vector Machines)
也就是说,线性(软间隔)支持向量机包含线性可分(硬间隔)支持向量机
【软间隔支持向量机学习算法的原始形式】
软间隔最大化
软间隔最大化(Soft Margin Maximization)同样是找到使所有样本点的几何间隔的最小值最大的分离超平面,即寻找最大间隔分离超平面
对于硬间隔最大化中的原始问题:
线性近似可分意味着某些样本点 $(\mathbf{x}_i,y_i)$ 不能满足函数间隔大于等于 $1$ 的约束条件 $y_i(\boldsymbol{\omega}\cdot\mathbf{x}+\theta)-1\geq 0$
为解决这个问题,可以对每个样本点 $(\mathbf{x}_i,y_i)$ 引入一个松弛变量 $\xi_i\geq 0$,使得函数间隔加上松弛变量大于等于 $1$,即:
同时,对每个松弛变量 $\xi_i$,支付一个代价 $\xi_i$,使得目标函数由 $\frac{1}{2}||\boldsymbol{\omega}||_2^2$ 变为:
其中,$C>0$ 为惩罚系数,由具体的应用问题决定,$C$ 越大说明对误分类的惩罚越大
此时的目标函数有两层含义,一是使 $\frac{1}{2}||\boldsymbol{\omega}||_2^2$ 尽量小,即令几何间隔尽量大,二是令误分类点的个数尽量小,并通过惩罚系数 $C$ 来调和二者的关系
于是可以得到约束最优化问题:
上述的约束最优化问题是一个凸二次规划(Convex Quadratic Programming)问题,相对于硬间隔最大化,其被称为软间隔最大化
需要注意的是,对于上述的凸二次规划问题,关于 $(\boldsymbol{\omega},\theta,\boldsymbol{\xi})$ 的解是存在的,同时 $\boldsymbol{\omega}$ 的解是唯一的,但 $\theta$ 的解可能不唯一,其存在于一个区间中
最大间隔法
软间隔支持向量机的学习算法为最大间隔法
输入:容量为 $n$ 的训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_n,y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $m$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}=\{+1,-1\}$
输出:最大间隔分离超平面、分类决策函数
算法步骤:
Step1:构造并求解如下约束最优化问题
求得最优解 $\boldsymbol{\omega}^*$ 和 $\theta^*$
Step2:根据最优解 $\boldsymbol{\omega}^*$ 和 $\theta^*$,得到分离超平面
以及分类决策函数
【软间隔支持向量机学习算法的对偶形式】
对偶问题的转化
为求解软间隔支持向量机的最优化问题:
将其作为原始最优化问题,应用拉格朗日对偶性,通过求解对偶问题来得到原始问题的最优解
首先,构建拉格朗日函数,即为每一个不等式约束引入拉格朗日乘子 $\lambda_i\geq 0$ 和 $\mu_i\geq 0$,即:
其中,$\boldsymbol{\lambda}=(\lambda_1,\lambda_2,\cdots,\lambda_n)^T$ 和 为拉格朗日乘子向量
此时,根据拉格朗日对偶性,原始问题的对偶问题就变为了极大极小问题,即:
因此,为了得到对偶问题的解,就要先求拉格朗日函数 $L(\boldsymbol{\omega},\theta,\boldsymbol{\xi},\boldsymbol{\lambda},\boldsymbol{\mu})$ 对 $\boldsymbol{\omega}$、$\theta$、$\boldsymbol{\xi}$ 的极小,再求对 $\boldsymbol{\lambda}$、$\boldsymbol{\xi}$ 的极大
对偶问题中的极小问题
对于对偶问题中的极小问题:
令拉格朗日函数 $L(\boldsymbol{\omega},\theta,\boldsymbol{\xi},\boldsymbol{\lambda},\boldsymbol{\mu})$ 分别对 $\boldsymbol{\omega}$、$\theta$、$\boldsymbol{\xi}$ 求偏导,并令其等于 $0$,即:
可得:
将上式带回拉格朗日函数 $L(\boldsymbol{\omega},\theta,\boldsymbol{\xi},\boldsymbol{\lambda},\boldsymbol{\mu})$ 中,有:
故有:
对偶问题中的极大问题
对于对偶问题中的极大问题:
即为对偶问题,有:
利用等式约束 $C-\lambda_i-\mu_i=0$,消去 $\mu_i$,有:
再将该问题的目标函数由求极大转为求极小,就得到如下的等价的对偶最优化问题:
可以发现,原始问题是凸优化问题,且 Slater 条件成立,那么,原始问题强对偶性成立,即求解原始问题可以转换为求解上述的对偶问题
假设上述的对偶问题对 $\boldsymbol{\lambda}$ 的一个解为 $\boldsymbol{\lambda}^* = (\lambda_1^*,\lambda_2^*,\cdots,\lambda_n^*)^T$,那么根据 KKT 条件,可得:
故而有:
同时,若存在 $0<\lambda_j^*<C$,对此 $j$ 有:
将 $\boldsymbol{\omega}^* = \sum\limits_{i=1}^n \lambda_i^* y_i\mathbf{x}_i$ 带入到上式,并由 $y_j^2=1$,可得:
故而,分离超平面可写为:
分类决策函数可写为:
对偶学习算法
根据上述对偶问题的推导,可得到软间隔支持向量机的对偶学习算法
输入:容量为 $n$ 的近似线性可分的训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_n,y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $m$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}=\{+1,-1\}$
输出:最大间隔分离超平面、分类决策函数
算法步骤:
Step1:选择惩罚系数 $C>0$,构造并求解如下约束最优化问题(原始问题的对偶问题)
求得最优解 $\boldsymbol{\lambda}^* = (\lambda_1^*,\lambda_2^*,\cdots,\lambda_n^*)^T$
Step2:根据最优解 $\boldsymbol{\lambda}^*$,计算分离超平面的法向量 $\boldsymbol{\omega}^*$ 和截距 $\theta^*$
对于法向量 $\boldsymbol{\omega}^*$,有:
选择最优解 $\boldsymbol{\lambda}^*$的一个分量 $\lambda_j^*$,满足 $0<\lambda_j^*<C$,计算截距 $\theta^*$,有:
Step3:根据最优解 $\boldsymbol{\omega}^*$ 和 $\theta^*$,得到分离超平面
以及分类决策函数
对于 Step1 中的凸二次规划问题,可使用 SMO 算法来求解,关于 SMO 算法,详见:序列最小最优化算法 SMO
在 Step2 中,对任一满足 $0<\lambda_j^*<C$ 的 $\lambda_j^*$,均可求出截距 $\theta^*$,从理论上来说,原始问题对 $\theta$ 的解可能不唯一,然而在实际应用中,往往只会出现上述算法叙述的情况
【支持向量与间隔边界】
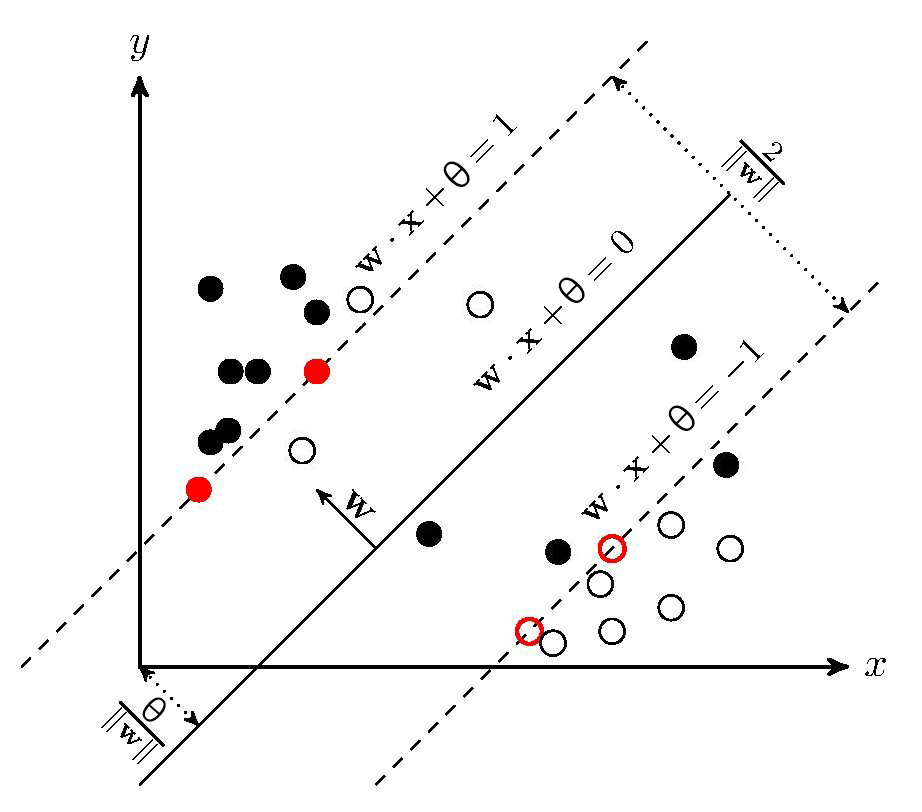
在线性不可分的情况下,对于对偶问题的解 $\boldsymbol{\lambda}^* = (\lambda_1^*,\lambda_2^*,\cdots,\lambda_n^*)^T$ 中对应 $\lambda_i^*>0$ 的样本点 $(\mathbf{x}_i,y_i)$ 的实例 $\mathbf{x_i}$ 称为软间隔的支持向量(Support Vector)
如图所示,红线标出的是支持向量 $\mathbf{x}_i$ 到间隔边界的距离 $\frac{1}{||\boldsymbol{\omega}_2^2||}\xi_i$

此外,分类决策函数:
根据 KKT 条件,对于任意样本 $(\mathbf{x}_i,y_i)$,总有 $\lambda_i=0$ 或 $y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)=1-\xi_i$
- 当 $\lambda_i=0$ 时,该样本不会在分类决策函数 $f(\mathbf{x})$ 求和中出现,也就不会对 $f(\mathbf{x})$ 造成任何影响
- 当 $\lambda_i>0$ 时,必有 $y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)=1-\xi_i$,所对应的样本点正好位于间隔边界上,是一个支持向量
- 若 ,则 $\mu_i>0$,进而有 $\xi_i=0$,相应的支持向量 $\mathbf{x}_i$ 恰好落在间隔边界上
- 若 $\lambda_i=C$,则 $\mu_i=0$,此时若 $\xi_i=0$,即分类正确,$\mathbf{x}_i$ 位于间隔边界与分离超平面之间
- 若 $\lambda_i=C$,则 $\mu_i=0$,此时若 $\xi_i=1$,$\mathbf{x}_i$ 位于分离超平面上
- 若 $\lambda_i=C$,则 $\mu_i=0$,此时若 $\xi_i>1$,即分类错误,$\mathbf{x}_i$ 位于分离超平面误分一侧
【软间隔支持向量机的等价问题】
最优化问题
对于软间隔支持向量机来说,其模型为分离超平面 $S:\boldsymbol{\omega}^*\cdot \mathbf{x}+\theta^*=0$ 以及分类决策函数 $f(\mathbf{x}) = \text{sign}(\boldsymbol{\omega}^*+\theta^*)$,学习策略为软间隔最大化,学习方法为凸二次规划
对于原始问题:
其等价于最优化:
证明:
对于最优化问题:
取 $\xi_i=\max(0,1-y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta))$,当 $1-y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)>0$ 时,有 $\xi_i>0$,进而有:
当 $1-y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)\leq0$ 时,有 $\xi_i=0$,进而有:
此时,满足原始问题的不等式约束,故最优化问题可写为:
进一步,取 $\lambda=\frac{1}{2C}$,则有:
与原始问题等价
反之,也可将原始问题表示为上述的最优化问题
合页损失函数
对于最优化问题
其中,目标函数第一项中的 $\max(0,1-y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta))$ 被称为合页损失函数(Hinge Loss Function),当样本点 $(\mathbf{x}_i,y_i)$ 被正确分类且函数间隔 $y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)>1$ 时,损失是 $0$,否则损失是 $1-y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)$,第二项 $\lambda||\boldsymbol{\omega}||_2^2$ 是正则化项
如下图所示,横轴是函数间隔 $y(\boldsymbol{\omega}\cdot \mathbf{x}+\theta)$,纵轴是损失,函数的形状如同一个合页,因此被称为合页损失函数,图中还画出了 0-1 损失函数,可以认为其是二分类问题真正的损失函数,合页损失函数是 0-1 损失函数的上界
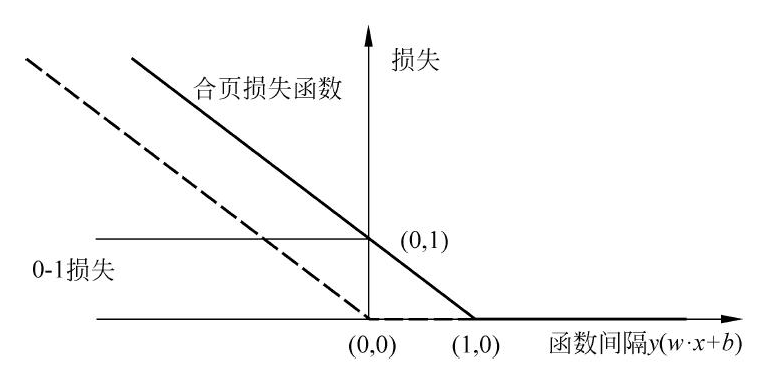
由于 0-1 损失函数不是连续可导的,直接优化由其构成的目标函数较为困难,可以认为软间隔支持向量机是由优化 0-1 损失函数的上界(合页损失函数)构成的目标函数
此外,图中的虚线代表的是感知机中所使用的感知损失函数(Perceptron Loss Function)
当样本点 $(\mathbf{x}_i,y_i)$ 被正确分类时,损失是 $0$,否则损失是 $-y_i(\boldsymbol{\omega}\cdot \mathbf{x}_i+\theta)$,相比之下,合页损失函数不仅要求分类正确,而其确信度足够高时是损失才是 $0$,即合页损失函数对学习有更高的要求
【sklearn 实现】
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现软间隔支持向量机

1 | import pandas as pd |

