References:
【AdaBoost 自适应提升算法】
AdaBoost 算法是自适应提升(Adaptive Boosting)算法的缩写,其是 Boosting 算法族的一种
其中,自适应(Adaptive)体现在前一个个体学习器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个个体学习器,同时在每一轮中加入一个新的弱学习器,直到得到某个预定的足够小的错误率或达到预定的最大迭代次数
对于 Bootsing 提升法的加法模型:
而 AdaBoost 算法是损失函数为指数损失函数 $\exp(-yf(\mathbf{x}))$ 的 Boosting 算法
关于 Boosting 算法,详见:Boosting 提升算法
【AdaBoost 的最优化问题】
对于给定的容量为 $n$ 的训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_n,y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $m$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}=\{+1,-1\}$,第 $t$ 轮从训练集中学习的弱学习器为 $G_t(\mathbf{x})$
假设经过 $t-1$ 轮前向分步法已经得到 $f_{t-1}(\mathbf{x})$:
在第 $t$ 轮迭代得到 $\alpha_t$ 和 $G_{t}(\mathbf{x})$,有:
那么,现在的目标是使前向分步法得到的 $\alpha_t$ 和 $G_t(\mathbf{x})$ 使 $f(\mathbf{x})$ 在训练集 $D$ 上的指数损失最小,即:
由于 $\exp[-y_if_{t-1}(\mathbf{x}_i)]$ 既不依赖于 $\alpha$,也不依赖于 $G$,因此与最小化无关,故令 $\omega_{ti}=\exp[-y_if_{t-1}(\mathbf{x}_i)]$,那么上式可表示为:
需要注意的是,$\omega_{ti}$ 依赖于 $f_{t-1}(\mathbf{x})$,其会随着每一轮的迭代而发生改变
【AdaBoost 分类算法】
参数优化
对 AdaBoost 的最优化问题:
当第 $t$ 轮从训练集中学习的弱学习器 $G_t(\mathbf{x})$ 是分类器时,考虑如何达到最小的 $\alpha_t^*$ 和 $G_t^*(\mathbf{x})$
对于 $G_t^*(\mathbf{x})$,对 $\forall \alpha>0$,使上式最小的 $G(\mathbf{x})$ 由下式可得到:
也就是说,$G_t^*(\mathbf{x})$ 是使第 $t$ 轮训练数据分类误差率最小的分类器,即为 AdaBoost 分类算法的基本分类器 $G_t(\mathbf{x})$
之后,考虑 $\alpha_t^*$,有:
将 $G_t^*(\mathbf{x})$ 带入上式,并对 $\alpha$ 求导,同时令导数为 $0$,有:
对于二分类问题来说,第 $t$ 个弱分类器 $G_t(\mathbf{x})$ 在训练集上的分类误差率为:
那么,将上式展开并化简,有:
对 $e^\alpha \text{error}_t = e^{-\alpha}(1-\text{error}_t)$ 两边同取 $\ln$,有:
可得使优化问题最小的 $\alpha$,即:
可以看出,如果分类误差率 $\text{error}_t$ 越大,那么对应的弱分类器权重系数 $\alpha_t$ 就越小,也就是说,误差率大的分类器权重系数越小
权重更新
假设第 $t$ 个弱分类器的训练集权重系数为:
那么,利用前向分步法的更新公式 $f_t(\mathbf{x})=f_{t-1}(\mathbf{x})+\alpha_t G_t(\mathbf{x})$,更新后的第 $t+1$ 个弱分类器的训练集权重系数为:
其中,$Z_t=\sum\limits_{i=1}^n \omega_{ti} \exp[-\alpha_t y_i G_t(\mathbf{x}_i)]$ 被称为规范化因子,其保证了 $D_t$ 是一个概率分布
从上式可以看出,如果第 $i$ 个样本分类错误,那么 $y_iG_t(\mathbf{x}_i)<0$,导致样本权重在第 $t+1$ 个弱分类器中增大,反之,若分类正确,那么 $y_iG_t(\mathbf{x}_i)>0$,导致样本权重在第 $t+1$ 个弱分类器中减小
分类器
最终,根据学习器的加法模型:
即可得到最终分类器:
算法流程
下面给出 AdaBoost 分类算法的算法流程
输入:对于给定的容量为 $n$ 的训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_n,y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $m$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}=\{+1,-1\}$、弱分类算法
输出:分类学习器 $G(\mathbf{x})$
算法流程:
Step1:初始化训练集的权值分布
Step2:对 $T$ 个分类器进行迭代,即对 $t=1,2,\cdots,T$
1)使用权值分布为 $D_t$ 的训练集进行学习,得到弱分类器
2)计算第 $t$ 个弱分类器 $G_t(\mathbf{x})$ 上的分类误差率
3)计算第 $t$ 个弱分类器 $G_t(\mathbf{x})$ 的系数
4)更新第 $t+1$ 轮的训练集的权值分布
Step3:构建弱分类器的加法模型
Step4:得到最终分类器
【AdaBoost 回归算法】
AdaBoost 回归算法的推导流程与 AdaBoost 分类算法类似,这里不再给出
下面直接给出 AdaBoost 回归算法的算法流程:
输入:对于给定的容量为 $n$ 的训练集 $D=\{(\mathbf{x}_1,y_1),(\mathbf{x}_2,y_2),…,(\mathbf{x}_n,y_n)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $m$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(m)})\in \mathbb{R}^m$,输出 $y_i\in\mathcal{Y}$、弱回归算法
输出:回归学习器 $G(\mathbf{x})$
算法流程:
Step1:初始化训练集的权值分布
Step2:对 $T$ 个分类器进行迭代,即对 $t=1,2,\cdots,T$
1)使用权值分布为 $D_t$ 的训练集进行学习,得到弱回归器
2)计算第 $t$ 个弱回归器 $G_t(\mathbf{x})$ 上的最大误差
3)根据最大误差和选用的误差计算方法,计算第 $t$ 个弱回归器 $G_t(\mathbf{x})$ 对每个样本的相对误差
- 线性误差:$\text{error}_{ti} = \frac{|y_i-G_t(\mathbf{x}_i)|}{\text{Error}_t}$
- 平方误差:$\text{error}_{ti} = \frac{(y_i-G_t(\mathbf{x}_i))^2}{\text{Error}_t^2}$
- 指数误差:$\text{error}_{ti} = 1-\exp[\frac{-y_i+G_t(\mathbf{x}_i)}{\text{Error}_t}]$
4)计算第 $t$ 个弱回归器 $G_t(\mathbf{x})$ 的回归误差率
5)计算第 $t$ 个弱回归器 $G_t(\mathbf{x})$ 的系数
6)更新第 $t+1$ 轮的训练集的权值分布
Step3:得到最终回归器
其中,$g(\mathbf{x})$ 为所有 $\alpha_tG_t(\mathbf{x})$ 的中位数
【AdaBoost 的正则化】
通常来说,为防止 AdaBoost 出现过拟合,会加入正则化项,这个正则化项即学习率(Learning Rate)
对于前向分步法的更新公式的 $f_t(\mathbf{x})=f_{t-1}(\mathbf{x})+\alpha_t G_t(\mathbf{x})$,有:
其中,$\mu\in(0,1]$ 即为学习率
对于同样的训练集来说,较小的 $\mu$ 意味着需要更多的弱学习器的迭代次数,通常用学习率和迭代最大次数来一起决定算法的拟合效果
【sklearn 实现】
GBDT 回归算法
以 sklearn 中的波士顿房价数据集为例,选取其后两个特征来实现 AdaBoost 回归算法
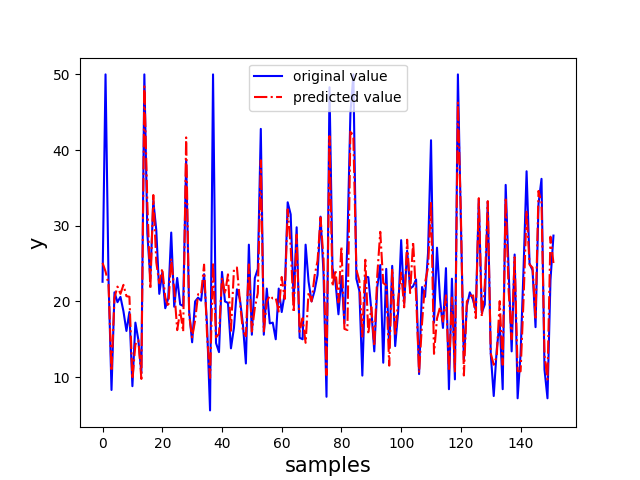
1 | import numpy as np |
GBDT 分类算法
以 sklearn 中的鸢尾花数据集为例,选取其后两个特征来实现 AdaBoost 分类算法

1 | import pandas as pd |

