【概述】
反向传播(Error Back Propagation,BP)算法,是迄今为止最成功的神经网络训练算法,其不仅可用于多层前馈神经网络中,还可用于其他神经网络,但通常说到 BP 神经网络时,一般是指用 BP 算法所训练的多层前馈神经网络,此外,在实际应用中,当使用神经网络建模时,大多使用 BP 算法进行训练
BP 算法是一种迭代学习算法,在迭代的每一轮中采用感知机学习算法对参数进行更新,其仍是基于梯度下降法,以目标的负梯度方向对参数进行调整
【符号假设】
对于给定的容量为 $N$ 的样本集 $D=\{(\mathbf{x}_1,\mathbf{y}_1),(\mathbf{x}_2,\mathbf{y}_2),…,(\mathbf{x}_N,\mathbf{y}_N)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $n$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})\in \mathbb{R}^n$,输出 $\mathbf{y}_i$ 具有 $m$ 个特征值,即:$\mathbf{y}_i=(y_i^{(1)},y_i^{(2)},…,y_i^{(m)})\in\mathcal{Y}=\mathbb{R}^{m}$,也就是说,输入样本由 $n$ 个特征描述,输出为 $m$ 维实值向量
由于 BP 神经网络的参数很多,为便于讨论,给出如下符号假设:
- 用 $n_l$ 表示网络层数
- 用 $L_l$ 表示第 $l$ 层,$L_1$ 是输入层,$L_{n_l}$ 是输出层,其他为隐藏层
- 用 $S_l$ 表示第 $l$ 层的神经元个数,输入层神经元个数 $S_1$ 为输入样本特征数 $n$,输出层神经元个数 $S_{n_l}$ 为输出特征个数 $m$
- 用 $w_{ij}^{[l]}$ 表示第 $l$ 层的第 $i$ 个神经元与第 $l+1$ 层的第 $j$ 个神经元的连接权重
- 用 $b_{i}^{[l]}$ 表示第 $l$ 层的第 $i$ 个神经元的偏置项(激活阈值)
- 用 $z_{i}^{[l]}$ 表示第 $l$ 层的第 $i$ 个神经元的权重累计
- 用 $a_i^{[l]}$ 表示第 $l$ 层的第 $i$ 个神经元的激活值(输出值)
- 用 $\hat{y}$ 表示神经网络的输出值
如下图所示,给出了一个层数 $n_l=4$,各层神经元个数 $S_1=4,S_2=4,S_3=4,S_4=2$ 的多层前馈网络结构
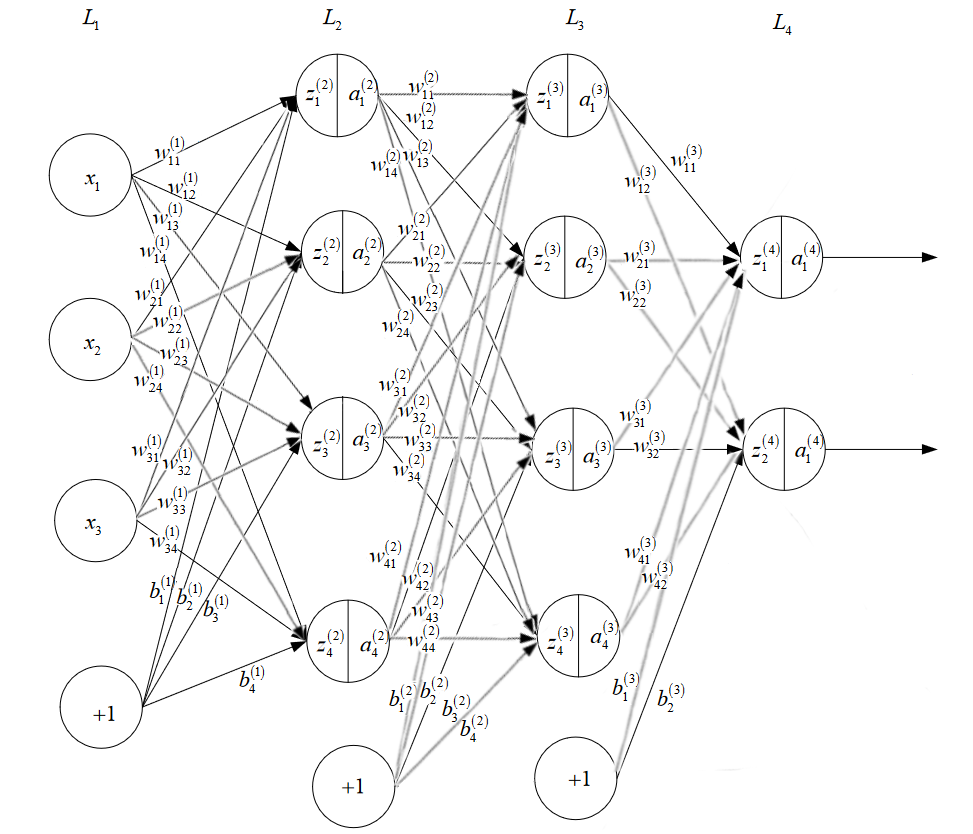
可以发现,网络中有 $(S_1+1)\times S_2 + (S_2+1)\times S_3+ (S_3+1)\times S_4 $ 个参数要确定,即:
- 输入层 $L_1$ 到隐藏层 $L_2$ 的 $S_1\times S_2$ 个权值(输入层 $L_1$ 第 $i$ 个神经元到隐藏层 $L_2$ 第 $j$ 个神经元:$w_{ij}^{[1]}$)
- 隐藏层 $L_2$ 到隐藏层 $L_3$ 的 $S_2\times S_3$ 个权值(隐藏层 $L_2$ 第 $i$ 个神经元到隐藏层 $L_3$ 第 $j$ 个神经元:$w_{ij}^{[2]}$)
- 隐藏层 $L_3$ 到输出层 $L_4$ 的 $S_3\times S_4$ 个权值(隐藏层 $L_3$ 第 $i$ 个神经元到输出层 $L_4$ 第 $j$ 个神经元:$w_{ij}^{[3]}$)
- 输入层 $L_1$ 神经元的偏置项($S_2$ 个 $b_i^{[1]}$)
- 隐藏层 $L_2$ 神经元的偏置项($S_3$ 个 $b_i^{[2]}$)
- 隐藏层 $L_3$ 神经元的偏置项($S_4$ 个 $b_i^{[3]}$)
【前向传播】
前向传播(Forward Propagation,FP)就是将神经网络上一层的输出作为下一层的输入,并计算下一层的输出,直到运算到输出层为止
以具有两层隐藏层的总共层数 $n_l=4$ 的神经网络为例,各层的神经元个数分别为 $S_1=n,S_2,S_3,S_4=m$,对于输入样例 $\mathbf{x}=(x^{(1)},x^{(2)},…,x^{(n)})\in \mathbb{R}^n$,前向传播过程如下:
输入层 $L_1$:$l=1$,对于输入层的 $S_1=n$ 个神经元,有
隐藏层 $L_2$:$l=2$,对于隐藏层的 $S_2$ 个神经元中的第 $j$ 个,权重累计为
经过激活函数 $f(\cdot)$ 后,输出值为
隐藏层 $L_3$:$l=3$,对于隐藏层的 $S_3$ 个神经元中的第 $j$ 个,权重累计为
经过激活函数 $f(\cdot)$ 后,输出值为
输出层 $L_4$:$l=4$,对于输出层的 $S_4=m$ 个神经元中的第 $j$ 个,权重累计为
经过激活函数 $f(\cdot)$ 后,输出值为
最终神经网络的输出值为:
不失一般性,对于第 $L_l$ 层的第 $j$ 个神经元,前向传播过程可写为:
对于 $N$ 个样本,将其矩阵化,有:
其中,各符号含义如下:
- 输入矩阵 $A_{S_{l-1}\times N}^{[l-1]}$:$N$ 个样本在第 $l-1$ 层的输出矩阵
- 权重矩阵 $(W_{S_{l-1}\times S_l}^{[l-1]} )^T$:$N$ 个样本在第 $l-1$ 层与第 $l$ 层的连接权重
- 偏置向量 $\mathbf{b}_{S_l \times 1}^{[l-1]}$:$N$ 个样本在第 $l-1$ 层的偏置向量
- 权重累计矩阵 $Z_{S_l\times N}^{[l]}$:$N$ 个样本在第 $l$ 层的权重累计矩阵
- 输出矩阵 $A_{S_l\times N}^{[l]}$:$N$ 个样本在第 $l$ 层的输出矩阵
【损失函数】
对于给定的容量为 $N$ 的样本集 $D=\{(\mathbf{x}_1,\mathbf{y}_1),(\mathbf{x}_2,\mathbf{y}_2),…,(\mathbf{x}_N,\mathbf{y}_N)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $n$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})\in \mathbb{R}^n$,输出 $\mathbf{y}_i$ 具有 $m$ 个特征值,即:$\mathbf{y}_i=(y_i^{(1)},y_i^{(2)},…,y_i^{(m)})\in\mathcal{Y}=\mathbb{R}^{m}$
假设存在一具有 $n_l$ 层的神经网络,各层神经元个数为 $S_1=n,S_2,S_3,\cdots,S_{n_l}=m$,对于样本集中的第 $k$ 个样本 $(\mathbf{x}_k,\mathbf{y}_k)$,其通过神经网络的输出为 $\hat{\mathbf{y}}_k=(\hat{y_k}^{(1)},\hat{y_k}^{(2)},…,\hat{y_k}^{(m)})$,那么平方损失函数为:
为便于求导,对 $E_k$ 整体乘以 $\frac{1}{2}$,此时得到的函数为第 $k$ 个样本的损失函数,即:
进一步,对于容量为 $N$ 的样本集,其损失函数为:
可以看出,损失函数 $J(w,b)$ 是惯有所有权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 的方程,要通过求损失函数最小来得到最佳的权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$,可以采用梯度下降法逐步下降迭代得到,即:
那么,只需要求出各权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 的偏导,即可对神经网络进行优化,但直接对上式进行计算十分困难,为此有了反向传播算法,从后向前求导进行更新
【反向传播】
反向传播(Backward Propagation,BP)是一种计算梯度的方法,原则上其可以计算任何函数的导数
在前向传播完成后,需要使用梯度下降法来对各权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 进行更新,但由于直接对神经网络的梯度下降公式求导十分困难,因此有了 BP 算法,其可以简单的理解为利用链式求导法则,从后向前逐层计算损失函数 $J(w,b)$ 对各权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 的梯度,然后进行更新,这也是算法被称为反向传播的原因
通过 BP 算法,最终得到的梯度下降方程为:
当 $l=1$ 时,$a_i^{[1]}$ 即为输入 $x^{(i)}$
其中,$\alpha$ 为学习率,$\delta_{j}^{[l]}$ 为第 $L_l$ 层第 $j$ 个神经元的误差,有:
关于具体的推导过程,见:附:详细推导
【算法流程】
输入:容量为 $N$ 的样本集 $D=\{(\mathbf{x}_1,\mathbf{y}_1),(\mathbf{x}_2,\mathbf{y}_2),…,(\mathbf{x}_N,\mathbf{y}_N)\}$,第 $i$ 组样本中的输入 $\mathbf{x}_i$ 具有 $n$ 个特征值,即:$\mathbf{x}_i=(x_i^{(1)},x_i^{(2)},…,x_i^{(n)})\in \mathbb{R}^n$,输出 $\mathbf{y}_i$ 具有 $m$ 个特征值,即:$\mathbf{y}_i=(y_i^{(1)},y_i^{(2)},…,y_i^{(m)})\in\mathcal{Y}=\mathbb{R}^{m}$,学习率 $0<\alpha\leq1$,迭代轮次 $\text{epoch}$,损失函数阈值 $\text{threshold}$
输出:连接权与阈值确定的多层前馈神经网络
算法步骤:
Step1:在 $(0,1)$ 范围内,随机初始化网络中所有的连接权重与偏置项
Step2:对于训练集中的每个样本 $(\mathbf{x}_k,\mathbf{y}_k)$,执行以下步骤:
1.根据网络结构,进行前向传播,计算网络输出 $\hat{\mathbf{y}}_k=(\hat{y_k}^{(1)},\hat{y_k}^{(2)},…,\hat{y_k}^{(m)})$
2.根据网络结构,进行反向传播,更新参数
1)对 $L_{n_l}$ 层,计算误差 $\boldsymbol{\delta}^{[n_l]}$
2)对 $L_l,l=n_l-1,n_l-2,\cdots,3,2$ 层,计算误差 $\boldsymbol{\delta}^{[l]}$
3)对连接权重与偏置进行更新
当 $l=1$ 时,$a_i^{[1]}$ 即为输入 $x^{(i)}$
Step3:重复 Step2,直到训练集的损失函数 $J(w,b)$ 达到要求的值,或完成迭代轮数
通过上述算法流程可以发现,对于每个训练集中的每个训练样本,BP 算法先将输入提供给输入层单元,然后逐层将信号前传,直到产生输出层结果(步骤 Step2.1)
之后,再计算输出层的误差(步骤 Step2.2),将误差逆向传播至隐藏层(步骤 Step2.3),根据隐藏层神经元的误差对连接权和阈值进行调整(步骤 Step2.4)
下图给出了一个多层前馈神经网络的 FP 与 BP 的完整过程
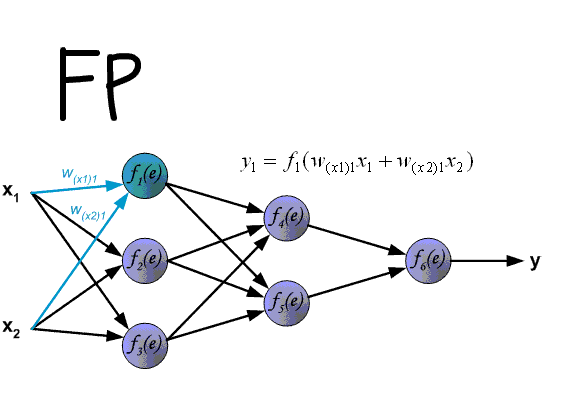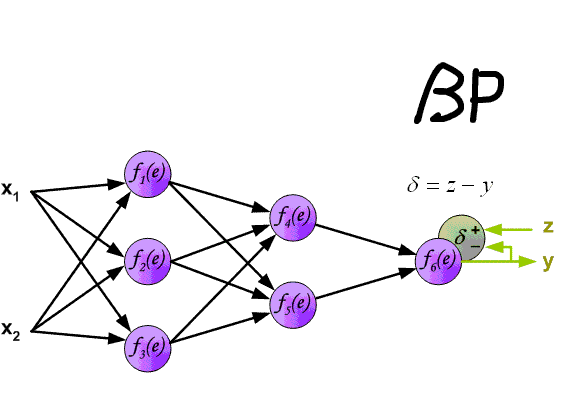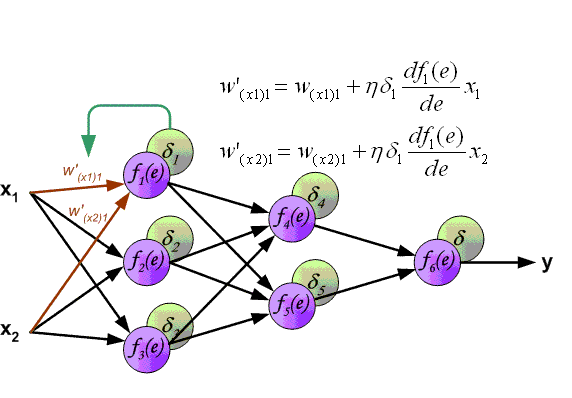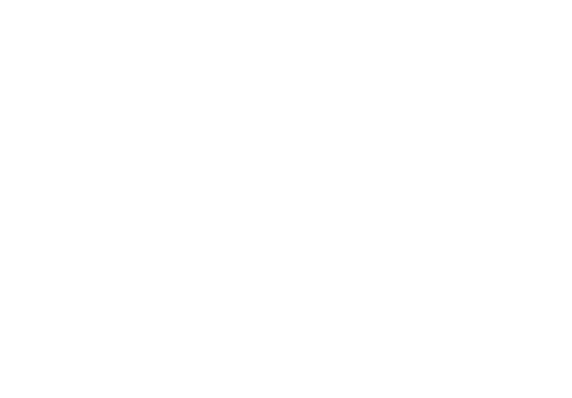
【实现】
采用向量化编程,实现下图所示的单隐藏层二分类神经网络,损失函数采用交叉熵损失函数,网络结构为:
- 输入层 $L_1$:两个神经元
- 隐藏层 $L_2$:四个神经元,采用 tanh 激活函数
- 输出层 $L_3$:一个神经元,采用 sigmoid 激活函数

实现步骤为:
- 定义网络结构
- 初始化连接权重与偏置
- 循环以下步骤,直到完成迭代轮数
- 前向传播
- 计算损失
- 反向传播获得梯度
- 梯度更新
代码如下:
1 |
|
【附:详细推导】
问题转化
对于一个层数为 $n_l$ 的神经网络,各层神经元个数为 $S_1=n,S_2,S_3,\cdots,S_{n_l}=m$,对损失函数求第 $l$ 层的各权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 的偏导,有:
此时,问题转化为求每个样本的损失函数 $E_k$ 关于各权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 的偏导
$L_{n_l-1}$ 层的偏导
对任一样本 $(\mathbf{x},\mathbf{y})$,有:
$\hat{\mathbf{y}}$ 是输出层 $L_{n_l}$ 的输出,其是关于 $L_{n_l-1}$ 层的 $w$ 和 $b$ 的函数,由此,考虑从 $L_{n_l-1}$ 层开始对损失函数求偏导,看能否找到规律
即对损失函数 $J(w,b)$,求第 $L_{n_l-1}$ 层关于各权重 $w_{ij}^{[n_l-1]}$ 的偏导,即:
根据前向传播,输出层 $L_{n_l}$ 的第 $k$ 个神经元的权重累计 $z_k^{[n_l]}$ 为:
那么,根据链式求导法则,有:
此时,第 $L_{n_l}$ 层第 $j$ 个的神经元差为:
对于最后的输出层来说,由于样本输出 $y^{(j)}$、由前向传播得来的神经元输出 $f(z_j^{[n_l]})$ 以及其导数是确定的,因此误差 $\delta_j^{[n_l]}$ 也能确定下来
$L_{n_l-2}$ 层的偏导
根据从 $L_{n_l-1}$ 层确定的误差 $\delta_j^{[n_l]}$,向前推第 $L_{n_l-2}$ 层对损失函数关于各权重的偏导,即对损失函数 $J(w,b)$,求第 $L_{n_l-2}$ 层关于各权重 $w_{ij}^{[n_l-2]}$ 的偏导,即:
根据前向传播,隐藏层 $L_{n_l-1}$ 的第 $k$ 个神经元的权重累计 $z_k^{[n_l-1]}$ 为:
那么,根据链式求导法则,有:
对于输出层 $L_{n_l}$ 的第 $k$ 个神经元,其权重累计 $z_k^{[n_l]}$ 受到前一层 $L_{n_l-1}$ 的所有神经元的权重累计 $z_i^{[n_l-1]}$ 的影响,故有:
由于第 $L_{n_l}$ 层第 $j$ 个神经元的误差为 $\delta_j^{[n_l]}=\Big[ f(z_j^{[n_l]})-y^{(j)} \Big]\cdot f’(z_j^{[n_l]})$,故有:
进一步,根据 $z_k^{[n_l]} = \sum\limits_{p=1}^{S_{n_l-1}} w_{pk}^{[n_l-1]}a_p^{[n_l-1]}+b_k^{[n_l-1]}$,有:
其中,$w_{jk}^{[n_l-1]}$ 是隐藏层 $L_{n_l-1}$ 第 $j$ 个神经元与输出层 $L_{n_l}$ 第 $k$ 个神经元的连接权重
综上,第 $L_{n_l-2}$ 层各权重 $w_{ij}^{[n_l-2]}$ 的偏导为:
此时,第 $L_{n_l-1}$ 层第 $j$ 个神经元的误差为:
此时,由于第 $L_{n_l}$ 层的误差 $\delta_k^{[n_l]}$ 、由前向传播得来的第 $L_{n_l-1}$ 层第 $j$ 个神经元的连接权重 $w_{jk}^{[n_l-1]}$ 以及神经元输出 $f(z_j^{[n_l-1]})$ 的导数是确定的,因此误差 $\delta_j^{[n_l-1]}$ 也能确定下来
梯度下降方程
根据第 $L_{n_l-1}$ 层、第 $L_{n_l-2}$ 层连接权重的推导,以此类推,可以得出第 $L_l$ 层的误差,即:
于是可得出,对于第 $L_l$ 层,损失函数关于各权重 $w_{ij}^{[l]}$ 和偏置 $b_i^{[l]}$ 的偏导为:
故最终的梯度下降方程为:
其中,$\alpha$ 为学习率,$\delta_{j}^{[l]} = \sum\limits_{k=1}^{S_{l+1}} \bigg[ \delta_k^{[l+1]} \cdot w_{jk}^{[l]} \cdot f’(z_j^{[l]}) \bigg]$ 为第 $L_l$ 层第 $j$ 个神经元的误差

