Reference
函数执行环境标识符
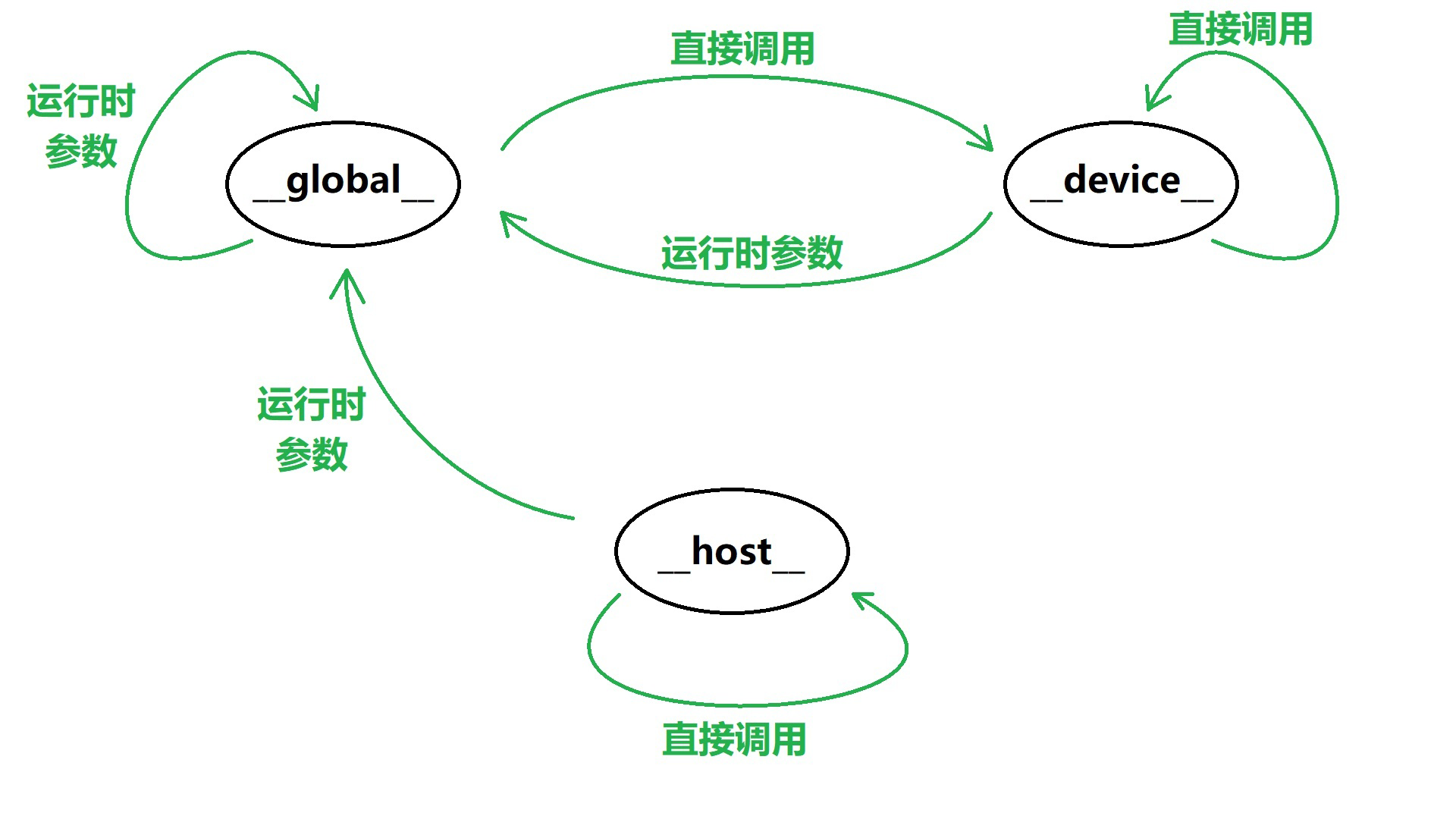
由于 GPU 是异构模型,所以需要区分 host 端和 device 端上的代码,在 CUDA 中是通过函数类型限定词开区别 host 和 device 上的函数,主要的三个函数类型限定词如下:
__global__:在 device 端执行,host 端中调用(某些 GPU 允许从 device 端调用),返回类型必须是 void,不支持可变参数参数,不能成为类成员函数__device__:在 device 端执行,device 端调用,不能与__global__同时使用__host__:在 host 端执行,host 端调用,一般省略不写,不能与__global__同时使用,但可与__device__同时使用(此时会在 device 端和 host 端都编译)
三个标识符标识的函数执行位置与调用位置如下表所示
| 标识符 | 执行位置 | 调用位置 |
|---|---|---|
__global__ |
device | host & device(arch>3.2) |
__device__ |
device | device |
__host__ |
host | host |
用拓扑结构图来表示有:
核函数
使用 __global__ 修饰的函数被称为核函数(Kernel Function),在调用时需要用 <<<grid, block>>> 来分配 block 数与线程数,在核函数加载后,会按如下步骤执行:
- 将 grid 分配到一个 device
- 根据
<<<grid, block>>>内的执行设置的grid,将 block 分配到流式多处理器(SM)上,一个 block 内的线程一定会在同一个 SM 内,一个 SM 内可有多个 block - 根据
<<<grid, block>>>内的执行设置的block,Wrap 调度器会调用线程,其会将 32 个线程分为一组,称为一个 Wrap - 每个 Wrap 会被分配到 32 个 core 上运行
同时,核函数是异步的,即 host 端不会等待核函数执行完就执行下一步
如下给出了一个简单的 CUDA 程序
1 |
|
对于 grid 和 block 的大小设置并没有统一标准,通常根据实际需要自行配置,对于 dim-1 的 grid 和 dim-1 的 block,推荐设置如下
1 | dim3 blockSize(128); |
同步函数
当某个线程执行到同步函数时,会进入等待状态,直到同一 block 中所有线程都执行到这个函数为止,相当于一个线程同步点,确保一个 block 中所有线程都达到同步,然后线程进入运行状态
在 CUDA 中,由于核函数是异步的,host 端不会等待核函数执行完就执行下一步,为避免核函数未执行完出现错误,可以使用以下三种同步函数来停住 host 端线程,等待 CUDA 中的操作完成
cudaDeviceSynchronize():停止 host 端执行,直到 device 端完成 CUDA 的任务,包括核函数、数据拷贝等cudaThreadSynchronize():与cudaDeviceSynchronize()作用类似,但其不能被核函数调用

