【存在性定理】
弱单向函数与强单向函数的关系中函数 $g$ 的构造与证明说明,只要单向函数存在,就可以构造出一个弱单向但不是强单向的函数。因此,不能认为所有单向函数都是强单向函数
但是,也不能认为所有单向函数都只能是弱单向函数。事实上,弱单向函数的存在可以推出强单向函数的存在
Theorem:弱单向函数存在当且仅当强单向函数存在。
其中一个方向是直接的:如果强单向函数存在,那么弱单向函数当然存在,因为强单向性本身就是更强的反演困难性要求
但更重要的是另一个方向:如果弱单向函数存在,那么也可以通过某种困难性放大方法构造出强单向函数
此外,从效率角度看,二者并不真正等价。因为把弱单向函数转化为强单向函数的方法并不实用,它主要是一个理论上的存在性证明,而不是一个高效可用的构造方法。对于某些特殊类型的单向函数,例如单向置换以及其他特定类别的单向函数,存在更加高效的弱到强转换方法。
【弱单向函数到强单向函数的构造】
函数构造
定义:
其中 $\mathrm{poly}(n)$ 是弱单向函数定义中给出的多项式。
对于输入 $(x_1,\ldots,x_{t(n)})$,其中每个块满足:
定义函数 $g$ 为:
也就是说,函数 $g$ 将输入划分成 $t(n)$ 个长度为 $n$ 的块,然后对每个块分别应用函数 $f$。由于每个块长度为 $n$,块数为 $t(n)=n\cdot \mathrm{poly}(n)$,所以 $g$ 的总输入长度为:
函数 $g$ 显然可以在多项式时间内计算,因为只需要把输入分块,然后对每个块调用一次函数 $f$ 即可。
直观困难性
反演函数:
要求同时找到每个 $f(x_i)$ 的一个原像,即反演函数 $g$ 需要同时解决多个 $f$ 的反演问题。
直观来看,由于 $f$ 是弱单向函数,每个单独的 $f(x_i)$ 至少有 $\frac{1}{\mathrm{poly}(n)}$ 的失败概率。如果反演算法必须独立地反演每个块,那么成功反演所有块的概率至多为:
这是可忽略的,因此在这种直觉下,函数 $g$ 应该是强单向函数。
但是,这个直观论证并不严谨。原因在于,反演函数 $g$ 的算法不一定逐块独立工作,它可能以某种全局方式处理整个输入
因此,不能假设它在每个 $f(x_i)$ 上独立运行,也不能直接把每个块上的失败概率相乘,证明函数 $g$ 是强单向函数需要更精细的归约论证
基本思路
证明采用反证法。
假设 $g$ 不是强单向函数。根据强单向函数定义的否定形式,存在一个概率多项式时间算法 $B’$ 和一个多项式 $\mathrm{poly}’(\cdot)$,使得对于无穷输入长度 $m$,都有:
即 $B’$ 能够以不可忽略概率反演函数 $g$。
接下来只需要利用这个反演函数 $g$ 的算法 $B’$,构造一个反演函数 $f$ 的概率多项式时间算法 $A’$。如果构造成功,并且 $A’$ 能够以大于 $1-\frac{1}{\mathrm{poly}(n)}$ 的概率反演函数 $f$,就会与 $f$ 是弱单向函数矛盾。
这里的关键是:不假设 $B’$ 以什么方式反演函数 $g$,也不假设它逐块独立工作,只是把 $B’$ 当作黑盒来使用。
证明
反证假设
假设函数 $g$ 不是强单向函数。那么,存在一个概率多项式时间算法 $B’$ 和一个多项式 $\mathrm{poly}’(\cdot)$,使得对于无穷多个输入长度 $m$,有:
也就是说,算法 $B’$ 能够以不可忽略概率反演函数 $g$。
由于函数 $g$ 的输入由 $t(n)=n\mathrm{poly}(n)$ 个长度为 $n$ 的块组成,所以这里主要考虑的输入长度:
接下来利用 $B’$ 构造一个概率多项式时间算法 $A’$,使其能够以过高概率反演函数 $f$,从而与 $f$ 的弱单向性矛盾。
随机过程
给定输入 $y$,将 $y$ 视为某个 $f(x)$,并令 $n=|y|$。定义一个随机过程 $I$,其目标是找到某个 $z$,使得:
具体来说,随机过程 $I$ 对每个位置 $i=1,\ldots,t(n)$ 执行如下操作:
(1)均匀且独立地随机选择:
(2)构造一个函数 $g$ 的输出形式,但把第 $i$ 个位置替换成待反演的 $y$,即:
(3)将该输入交给 $B’$,得到:
(4)检查第 $i$ 个输出块是否满足:
若满足,则输出 $z_i$,随机过程成功。
这个构造的含义是:如果 $y=f(x)$,那么把 $y$ 嵌入到 $g$ 的某一个坐标中,让 $B’$ 尝试反演整个 $g$ 的输出。只要 $B’$ 成功反演整个 $g$,那么它在第 $i$ 个位置上给出的 $z_i$ 就必须满足 $f(z_i)=y$,从而得到 $f$ 的一个原像。
反演算法构造
算法 $A’$ 在输入 $y$ 时,重复运行随机过程 $I$ 共 $a(n)$ 次,其中:
只要某一次运行 $I$ 成功,算法 $A’$ 就输出对应结果;如果所有运行都失败,则算法 $A’$ 失败。
这里的 $\mathrm{poly}(\cdot)$ 来自弱单向函数 $f$ 的定义,表示任意高效反演算法反演 $f(U_n)$ 时的失败概率下界;$\mathrm{poly}’(\cdot)$ 来自反证假设,表示算法 $B’$ 反演 $g$ 时的成功概率下界。
重复运行 $I$ 的作用是放大成功概率,只要过程 $I$ 在某些输入上有非零且足够大的成功概率,那么重复运行足够多次后,算法 $A’$ 就能够以接近 $1$ 的概率反演这些输入。
成功概率分析
为了分析 $A’$ 的成功概率,定义集合 $S_n$。集合 $S_n$ 包含那些随机过程 $I$ 能以相对明显概率成功反演的输入 $x$,即:
这里的概率只针对过程 $I$ 的内部随机性。
直观上,对于这些 $x$,随机过程 $I$ 在输入 $f(x)$ 时,能够以大于 $\frac{n}{a(n)}$ 的概率成功找到 $f(x)$ 的一个原像。
如果能够证明以下两个结论:
- 如果 $x\in S_n$,那么重复运行 $I$ 的算法 $A’$ 几乎一定能反演函数 $f(x)$
- 对于与反证假设对应的无穷多个 $n$,集合 $S_n$ 占据了绝大多数长度为 $n$ 的字符串
那么,将这两个结论组合起来,就能够推出:对于无穷多个 $n$,算法 $A’$ 能够以大于 $1-\frac{1}{\mathrm{poly}(n)}$ 的概率反演函数 $f(U_n)$。
这与函数 $f$ 是弱单向函数的假设矛盾,因为弱单向函数要求任意概率多项式时间算法反演 $f(U_n)$ 的失败概率至少为 $\frac{1}{\mathrm{poly}(n)}$。
因此,只需要证明上述两个结论,就能推出反证假设不成立,从而说明函数 $g$ 是强单向函数。
结论证明
结论一
对于上述的结论一,可形式化地写为:
Claim:对于 $\forall x\in S_n$,有:
对于任意 $x\in S_n$,根据 $S_n$ 的定义,随机过程 $I$ 在输入 $f(x)$ 时成功概率大于 $\frac{n}{a(n)}$,算法 $A’$ 会重复运行 $I$ 共 $a(n)$ 次。因此,$A’$ 全部失败的概率至多为:
利用上界估计:
所以,$A’$ 在输入 $f(x)$ 时成功的概率大于 $1-2^{-n}$,即:
这说明:只要 $x\in S_n$,算法 $A’$ 就能以极高概率反演函数 $f(x)$。
结论二
对于上述的结论二,可形式化地写为:
Claim:对于无穷多个充分大的 $n\in \mathbb{N}^{+}$,有:
反证假设
采用反证法证明上述结论。假设:
那么随机选取一个 $n$ 位字符串时,它落入 $S_n$ 的概率至多为:
记 $B’$ 反演函数 $g$ 的成功概率为:
根据反证假设,因为 $g$ 不是强单向函数,所以对无穷多个 $n$ 有:
事件划分
接下来把随机变量 $U_{n^2\mathrm{poly}(n)}$ 看成 $t(n)=n\mathrm{poly}(n)$ 个长度为 $n$ 的随机块:
其中,每个 $U_n^{(i)}$ 都在 ${0,1}^n$ 上均匀分布,且彼此独立。
将 $B’$ 成功反演函数 $g$ 的事件分为两类:
- $B’$ 成功反演 $g$,并且至少有一个输入块落在 $S_n$ 的补集 $\overline{S_n}$ 中
- $B’$ 成功反演 $g$,并且所有输入块都落在 $S_n$ 中
记这两部分成功概率分别为 $s_1(n)$ 和 $s_2(n)$,即:
这两个事件互不相交,并且覆盖了 $B’$ 成功反演 $g$ 的所有情况,因此:
接下来分别对 $s_1(n)$ 和 $s_2(n)$ 给出上界,并说明它们的和会小于反证假设中 $B’$ 反演 $g$ 的成功概率下界,从而推出矛盾。
$s_1(n)$ 的上界
$s_1(n)$ 表示:$B’$ 成功反演函数 $g$,并且至少有一个输入块落在 $\overline{S_n}$ 中。
如果某个块 $x\notin S_n$,那么根据 $S_n$ 的定义,过程 $I$ 在输入 $f(x)$ 时成功概率不超过:
另一方面,过程 $I$ 正是通过把待反演的 $f(x)$ 放入 $g$ 的某一个位置,然后调用 $B’$ 来完成反演。因此,如果 $B’$ 在某个包含 $f(x)$ 的位置上成功反演函数 $g$,那么过程 $I$ 就能够成功反演函数 $f(x)$。
所以,对于任意 $x\notin S_n$ 和任意位置 $i$,有:
对 $s_1(n)$ 做上界估计。记事件:
则有:
利用并集上界:
对每个位置 $i$,继续按 $U_n^{(i)}$ 的具体取值展开:
根据条件概率公式可得:
而前面已经知道,当 $x\notin S_n$ 时,有 $P[E\mid U_n^{(i)}=x]\leq\frac{n}{a(n)}$,所以:
又由于 $\sum_{x\notin S_n}P[U_n^{(i)}=x]\leq 1$,因此:
再对所有 $n\mathrm{poly}(n)$ 个位置求和,即有:
这说明,如果成功事件中包含某个 $x\notin S_n$,那么这部分成功概率不会太大
$s_2(n)$ 的上界
$s_2(n)$ 表示:$B’$ 成功反演函数 $g$,并且所有输入块都落在 $S_n$ 中。
显然:
由反证假设:
由于一共有 $n\mathrm{poly}(n)$ 个独立随机块,所以:
该值可以利用指数上界估计为:
那么,对于充分大的 $n$,指数小量 $2^{-\frac{n}{2}}$ 小于多项式倒数级别的量,因此有:
故有:
矛盾推出
由 $s_1(n)$ 和 $s_2(n)$ 的上界可得:
而根据 $a(n)$ 的定义:
所以:
因此:
但这与“由函数 $g$ 不是强单向函数”得到的下界矛盾,所以反证假设不成立,结论二成立,即:
这说明,绝大多数输入 $x$ 都属于 $S_n$。
矛盾推出
现在结合结论一与结论二。
结论二表明,随机选择 $U_n$ 时,它落入 $S_n$ 的概率至少为:
结论一表明,一旦 $U_n\in S_n$,算法 $A’$ 反演函数 $f(U_n)$ 的成功概率至少为:
因此:
而对于充分大的 $n$,有:
所以:
这说明算法 $A’$ 能够以大于 $1-\frac{1}{\mathrm{poly}(n)}$ 的概率反演函数 $f$。
但是,根据 $f$ 是弱单向函数的定义,任意概率多项式时间算法反演函数 $f$ 的失败概率都至少为 $\frac{1}{\mathrm{poly}(n)}$。也就是说,任意概率多项式时间算法反演函数 $f$ 的成功概率都至多为 $1-\frac{1}{\mathrm{poly}(n)}$。这与上面对 $A’$ 的结论矛盾。
因此,假设“函数 $g$ 不是强单向函数”不成立,函数 $g$ 是强单向函数。
【玩具例子:由弱单向性到强单向性的证明思想】
基本问题
下面,通过一个简化的玩具例子,来说明上述定理证明中的核心思想
设 $f$ 是一个多项式时间可计算函数。如果对于任意概率多项式时间算法 $A’$,除了有限多个 $n$ 之外,算法 $A’$ 在输入 $f(U_n)$ 时无法找到 $f$ 的原像的概率至少为 $\rho(n)$,那么称函数 $f$ 是 $\rho$-单向($\rho$-One-Way)函数。
这里的单向性用反演失败概率来刻画,每一个弱单向函数都是某个多项式 $\mathrm{poly}(\cdot)$ 下的 $\frac{1}{\mathrm{poly}(\cdot)}$-单向函数,而强单向函数则可看作是可忽略函数 $\mu(\cdot)$ 下的 $(1-\mu(\cdot))$-单向函数。
玩具命题
考虑如下情形的一个玩具命题:
Proposition:假设函数 $f$ 是 $\frac{1}{3}$-单向的,即任何有效算法反演函数 $f$ 的失败概率至少为 $\frac{1}{3}$,成功概率至多为 $\frac{2}{3}$。那么,定义一个新的函数
其是 $0.55$-单向函数。
命题中,$0.55$ 略小于:
直观上,如果反演 $f$ 的成功率最多为 $2/3$,那么同时反演两个独立的 $f$ 输入,其成功率应该不超过:
但这个直观想法不能直接作为证明,因为反演 $g$ 的算法未必是分别反演两个坐标。
命题证明
反证假设
采用反证法。假设存在一个多项式时间算法 $A’$,它能够以大于 $0.45$ 的概率成功反演 $g(U_{2n})$。也就是说,当随机选择 $x_1,x_2\in\{0,1\}^n$ 时,算法 $A’$ 在输入 $g(x_1,x_2)=(f(x_1),f(x_2))$ 后,成功输出某个合法原像的概率大于 $0.45$。
为了简化讨论,先假设 $A’$ 是确定性算法。令:
考虑一个 $N\times N$ 的矩阵,矩阵的行对应 $x_1\in\{0,1\}^n$,列对应 $x_2\in\{0,1\}^n$。如果 $A’$ 在输入 $(f(x_1),f(x_2))$ 时成功反演 $g$,则将矩阵中对应位置 $(x_1,x_2)$ 标记为 $1$,否则标记为 $0$。
该反证假设等价于:矩阵中被标记为 $1$ 的位置比例大于 $45\%$。若记所有成功位置构成的集合为 $S\subseteq \{0,1\}^n\times\{0,1\}^n$,则有:
朴素观点及问题
一种朴素的观点是假设 $A’$ 会分别处理 $(f(x_1),f(x_2))$ 的两个分量,即算法 $A’$ 对第一个分量是否成功只取决于 $x_1$,对第二个分量是否成功只取决于 $x_2$。
如果这个假设成立,那么 $A’$ 的成功区域就会形成一个广义矩形(Generalized Rectangle):
其中 $R$ 表示第一坐标上能够成功反演的输入集合,$C$ 表示第二坐标上能够成功反演的输入集合。
由于 $f$ 是 $\frac{1}{3}$-单向的,任何有效算法反演 $f$ 的成功比例都不能超过 $\frac{2}{3}$,因此有:
显然有:
这就会与反证假设中成功位置比例大于 $45\%$ 矛盾。
但是,这个朴素假设无法证明。一般来说,算法 $A’$ 可能联合使用 $(f(x_1),f(x_2))$ 的两个分量,而不是分别反演它们。因此,$A’$ 的成功区域 $S$ 不一定是矩形,而可能是任意形状的子集。如下图所示,左子图表示朴素假设中的矩形成功区域 $R\times C$,右子图表示实际情况中需要处理的任意成功区域 $S$。
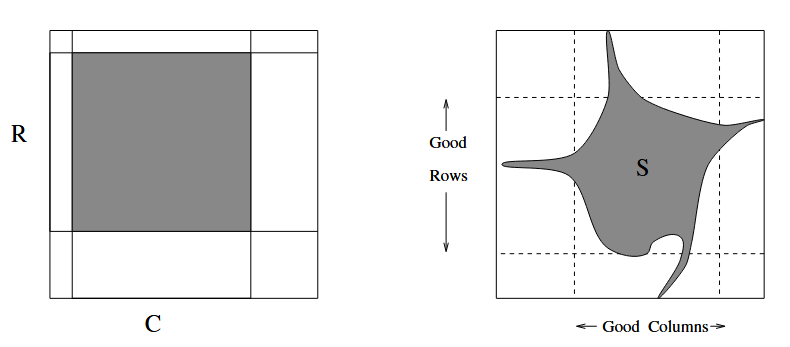
行列结构分析
好行与好列
由于成功区域 $S$ 可能是任意形状,证明无法直接用矩形面积估计,因此引入“好行”和“好列”的概念。
如果某一行 $x_1$ 中至少有 $0.1\%$ 的位置是 $1$,也就是至少有 $0.001N$ 个列 $x_2$ 使得 $A’$ 成功反演 $g(x_1,x_2)$,那么称这一行是好行(Good Row),否则称为坏行(Bad Row)。
类似地,如果某一列 $x_2$ 中至少有 $0.1\%$ 的位置是 $1$,则称这一列是好列(Good Column),否则称为坏列(Bad Column)。
比例上界
断言
通过这样定义,可以把 $A’$ 在二维输入上成功反演 $g$ 的问题,转化为在固定一个坐标时,$A’$ 是否仍然能以非忽略概率帮助反演另一个坐标的问题。换句话说,如果某一行是好行,那么在固定 $x_1$ 后,随机选择 $x_2$ 仍然有一定概率使得 $A’$ 成功反演,这就为构造反演 $f$ 的算法提供了可能。
因此,证明的关键是说明:好行和好列的数量都不能太多。否则,如果好行或好列占比过高,就可以利用 $A’$ 构造出一个高成功率反演 $f$ 的算法,从而违反函数 $f$ 是 $\frac{1}{3}$-单向的假设。
具体来说,需要证明如下断言:
Claim:好行的比例至多为 $66.8\%$,好列的比例也至多为 $66.8\%$。
断言证明
下面采用反证法证明好行的比例至多为 $66.8\%$,好列的证明是完全类似的。
反设好行的比例大于 $66.8\%$。构造一个反演 $f$ 的算法,该算法在输入 $y$ 时,重复执行以下步骤 $10000$ 次:
- 随机选择 $x_2\in\{0,1\}^n$
- 调用 $A’$,输入为 $(y,f(x_2))$,并得到输出 $(x’,x’’)$
- 如果 $f(x’)=y$,则输出 $x’$ 并停止
显然,这个算法是多项式时间算法。
对于任意一个好行 $x_1$,当输入为 $y=f(x_1)$ 时,由于这一行中至少有 $0.001N$ 个成功位置,所以随机选择 $x_2$ 时,单次调用 $A’$ 成功反演第一坐标的概率至少为 $0.001$。
因此,重复 $10000$ 次后仍然失败的概率至多为:
也就是说,对于每一个好行 $x_1$,该算法在输入 $f(x_1)$ 时的成功概率至少为:
如果好行的比例大于 $0.668$,那么当 $x_1\leftarrow U_n$ 时,该算法反演 $f(U_n)$ 的总成功概率至少为:
这与 $f$ 是 $\frac{1}{3}$-单向的假设矛盾,因为该假设意味着任何有效算法反演 $f$ 的成功概率都不能超过 $\frac{2}{3}$。
因此,好行的比例不能超过 $66.8\%$,同理,好列的比例也不能超过 $66.8\%$。
矛盾推出
一旦知道好行和好列的比例都不超过 $66.8\%$,剩下的部分就是组合计数。
首先,好行与好列的交叉区域中,最多有 $(0.668N)^2$ 个位置,即使这些位置全部都是 $1$,也只能贡献这么多成功位置。
其次,对于坏行而言,每一行中 $1$ 的数量最多为 $0.001N$;对于坏列而言,每一列中 $1$ 的数量最多为 $0.001N$。因此,坏行和坏列中能够贡献的 $1$-位置总数最多为 $2\cdot N\cdot 0.001N$。
因此,有:
这与反证假设 $|S|>0.45N^2$ 矛盾。
因此,不存在这样一个以大于 $0.45$ 概率反演 $g$ 的有效算法,命题得证。

