【非均匀多项式时间模型的两种观点】
非均匀多项式时间(Non-uniform Polynomial Time)模型,是一种比普通多项式时间模型更强的计算模型。在普通的多项式时间模型模型中,同一个算法必须处理所有输入长度,而在非均匀多项式时间模型中,计算过程可以针对不同输入长度 $n$ 使用不同的辅助信息
这种模型主要以否定的方式出现在密码学中。也就是说,如果能够证明即使敌手拥有这种更强的非均匀多项式时间模型的计算能力,也仍然无法完成某种攻击任务,那么该安全性结论就更强
直观来说,非均匀多项式时间模型允许机器在处理长度为 $n$ 的输入时,额外获得一段只依赖于输入长度 $n$ 的外部信息,这段信息称为建议(Advice)
建议串序列观点
形式化地,非均匀多项式时间模型可由一个双输入的多项式时间图灵机 $M$ 和一个建议串序列
组成。其中,每个建议串 $a_n$ 长度满足:
这里的建议串 $a_n$ 可以理解为外部提供给机器的建议,它与输入 $x\in\{0,1\}^n$ 一起被交给机器。因此,对于任意输入 $x$,机器实际执行的是:
也就是说,当输入 $x$ 的长度为 $|x|$ 时,机器会使用对应长度的建议字符串 $a_{|x|}$。需要注意的是,对于所有长度相同的输入,机器获得的是同一个建议字符串 $a_n$。因此,$a_n$ 只依赖于输入长度 $n$,而不依赖具体输入 $x$
直观上,建议串 $a_n$ 可以为长度为 $n$ 的输入提供某种额外帮助,但它不不能针对每一个具体输入单独变化。也就是说,它不是每个输入一个提示,而是每个输入长度一个提示
机器序列观点
非均匀多项式时间模型也可以从另一个角度理解:考虑一个无限的图灵机序列
其中,机器 $M_n$ 只处理长度为 $n$ 的输入。对于整个序列而言,$M_n$ 的描述长度与其在长度为 $n$ 的输入上的运行时间,均被关于 $n$ 的某个多项式统一限制
这两种观点是对应的。一方面,如果给定一对 $(M,(a_1,a_2,\cdots))$,那么可以得到一个机器序列
其中:
另一方面,如果给定一个机器序列 $M_1,M_2,\cdots$,那么也可以得到一对由通用图灵机 $U$ 和机器序列描述组成的表示:
并且满足:
因此,非均匀性可理解为:对于不同输入长度 $n$,可以使用不同的机器 $M_{n}$,而不要求这些机器必须由某个统一算法高效生成
【与概率多项式时间模型的关系】
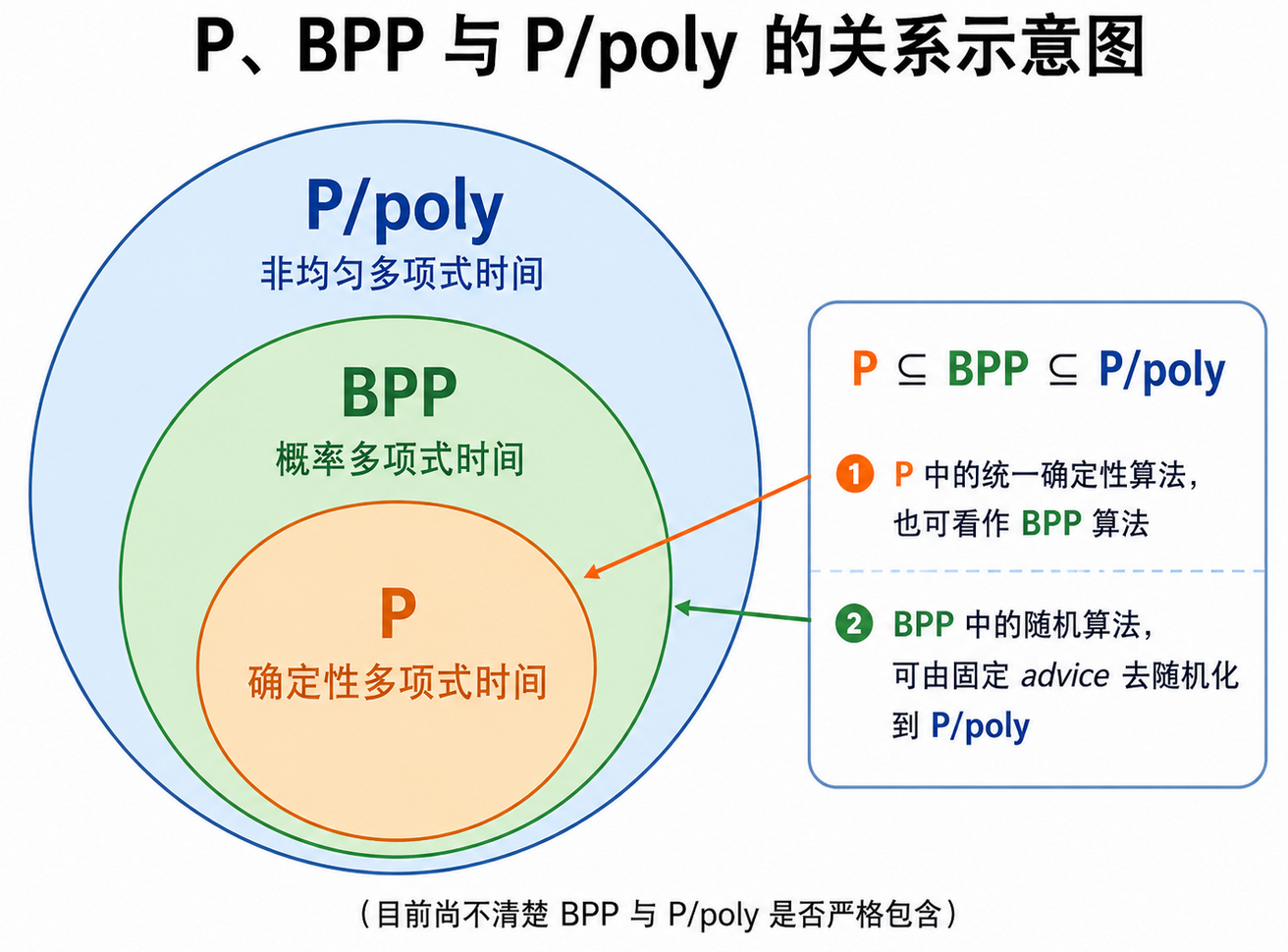
非均匀多项式时间模型通常被认为比概率多项式时间模型更强。例如语言识别问题,概率多项式时间图灵机能够识别的语言,非均匀多项式时间图灵机也能识别
因此,可以非正式的说:
在语言判定问题中,概率多项式时间模型能够实现的任务,非均匀多项式时间模型通常也能够实现
但这句话不能完全按照字面意思理解。例如,如果任务本身要求真实地产生随机性(如抛硬币),那么非均匀多项式时间模型并不能真实模拟这一随机性。因此,这个表述只是一个提示性的表述,其仅表示在许多语言识别场景中,可以通过固定合适的随机串,将概率算法转化为非均匀多项式时间模型中的确定性计算
【P/poly】
定义
非均匀多项式时间模型对应的复杂性类是 P/poly,其是一个语言类,表示能够被多项式长度建议串的多项式时间图灵机识别的语言类
若语言 $L\in \mathcal{P}/\mathrm{poly}$,则存在一个非均匀多项式时间机器序列 $M_1,M_2,\cdots$,使得:
- 存在一个多项式 $\mathrm{poly}(\cdot)$,使得对每个 $n$,机器 $M_n$ 的描述长度都不超过 $\mathrm{poly}(n)$
- 存在一个多项式 $\mathrm{poly}’(n)$,使得对每个 $n$,机器 $M_n$ 在任意长度为 $n$ 的输入上的运行时间都不超过 $\mathrm{poly}’(n)$
- 对每个 $n$ 和每个 $x\in\{0,1\}^n$,都有 $M_n(x)=1\Leftrightarrow x\in L$
这里的非均匀性体现在:对于每一个输入长度 $n$,都存在一个专门处理 $n$ 的机器 $M_n$,但并不要求存在一个高效算法来构造这些机器
P 与 P/poly
如果 $L\in \mathcal{P}$,说明存在一个统一的确定性多项式时间图灵机 $M$,它可以判断所有长度的输入是否属于 $L$。也就是说,对于任意字符串 $x$,都有:
而 P/poly 允许每个长度 $n$ 使用一个专门的机器 $M_n$,自然也允许每个长度都使用同一个机器。因此,可以令:
也就是说,每个 $M_n$ 都是同一个多项式时间图灵机 $M$,只是它专门被用于长度为 $n$ 的输入。这样显然满足 P/poly 的定义,因此有:
反过来,如果对复杂性类 P/poly 中的机器序列进一步要求:存在一个多项式时间算法 $G$,使得在输入 $1^n$ 时能够输出机器 $M_n$ 的描述,即:
那么这个机器序列 $M_1,M_2,\cdots$ 就不是单纯的存在了,而是可以由同一个算法 $G$ 统一生成。这时可以构造一个普通的多项式时间图灵机 $A$ 来判断 $x\in L$,即:
由于 $G$ 是多项式时间的,此时 $M_n$ 也变为多项式时间,所以 $A$ 是一个多项式时间图灵机,得到的实际上就是一种繁琐的 P 的定义方式。此时,非均匀性消失,模型退回到了普通的多项式时间模型
因此,P/poly 与 P 的关键差别在于:P/poly 只要求每个长度存在一个合适的机器或建议串,而不要求这些机器或建议串能够被统一高效生成
BPP 与 P/poly
若 $L\in\mathcal{BPP}$,则存在一个概率多项式时间图灵机 $M$ 可以以有界错误概率识别 $L$。假设机器在长度为 $n$ 的输入上使用 $m=\mathrm{poly}(n)$ 个随机比特,那么所有可能的随机串共有 $2^m$ 个。
对于固定输入 $x$,机器在不同随机串 $r\in \{0,1\}^{m}$ 下的输出可能不同。由于 $M$ 对于任意输入 $x$ 都有:
所以对于每个固定输入 $x$,至少有 $\frac{2}{3}$ 比例的随机串 $r$ 会让机器输出正确答案。也就是说,满足 $M_r(x) = \chi_L(x)$ 的随机串至少有 $\frac{2}{3} \cdot 2^m$ 个
但是,一个自然的问题是:是否存在一个随机串 $r$,能够同时适用于所有长度为 $n$ 的输入 $x\in\{0,1\}^n$
为了得到这样的随机串,需要先把概率多项式时间模型的错误概率降低到非常小。可以通过重复运行构造一个新的概率多项式时间图灵机 $M’$,使得对于每个输入 $x$,都有:
当 $|x|=n$ 时,对于每个固定长度为 $n$ 的输入 $x$,随机串 $r$ 使 $M’(x,r)$ 输出错误的概率小于 $2^{-n}$。由于长度为 $n$ 的输入总共有 $2^n$ 个,因此随机串 $r$ 使 $M’(x,r)$ 输出错误的数量小于:
由于输入的数量必须是整数,因此对于每个长度 $n$ 的输入 $x$,都可以找到一个固定随机串 $r_n$,使得对所有长度为 $n$ 的输入都不出错
于是,在非均匀多项式时间模型中,可以把这个 $r_n$ 作为长度为 $n$ 的建议字符串。对于长度为 $n$ 的输入 $x$,机器不再随机选择 $r$,而是直接使用建议串 $r_n$,运行:
而由于 $r_n$ 对所有长度为 $n$ 的输入都正确,因此这个机器可以确定性地判断 $x\in L$。于是,原本的 BPP 算法可以在非均匀多项式时间模型中被固定随机性,从而得到:
【非均匀多项式布尔电路族】
理解非均匀多项式时间模型的另一种方式,是非均匀多项式布尔电路族(Non-uniform Families of Polynomial-size Boolean Circuits)
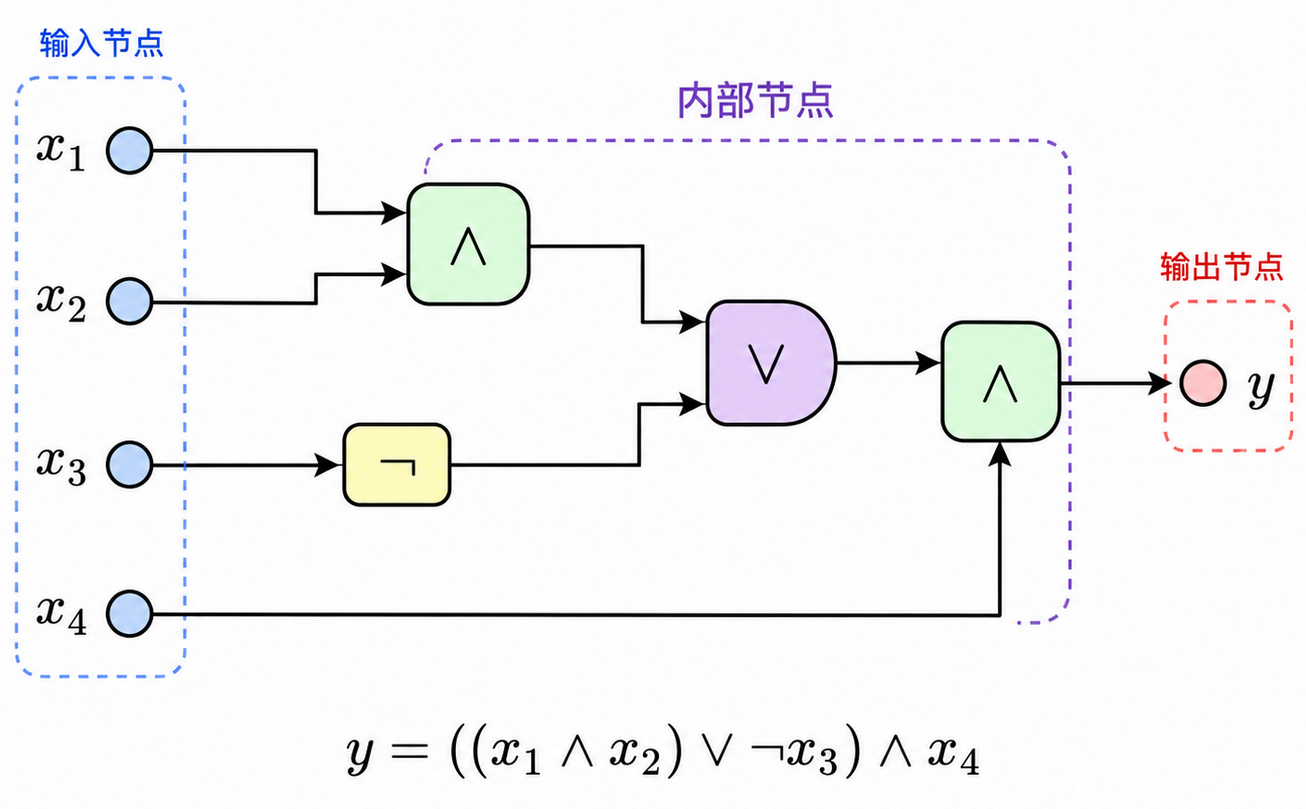
布尔电路
布尔电路(Boolean Circuit)是一个 DAG,其中内部结点标记为:
在图中,电路的规模(Size)通常用边数来度量,没有入边的结点称为输入结点(Input Nodes),没有出边的结点称为输出结点(Output Nodes),标记为 $\neg$ 的结点通常只有一个输入
在图中,电路的计算从输入结点开始,首先将输入比特放到输入结点上,每个输入结点放一个比特,然后按照电路结构计算内部结点的值。如果某个入度为 $d$ 的 $\wedge$ 结点的子结点取值为:
那么该结点的值为:
对于 $\vee$ 和 $\neg$ 结点,也以类似方式进行计算。最后,电路的输出从输出结点读出
多项式规模电路族
一个多项式规模电路族(Polynomial-size Circuit Family)是一个无限布尔电路序列:
使得对于每个 $n$,电路 $C_n$ 有 $n$ 个输入结点,且规模为 $\mathrm{poly}(n)$
非均匀性体现在:每个输入长度 $n$ 可以对应一个专门的电路 $C_n$。这与机器序列观点是一致的,机器序列中的 $M_n$ 专门处理长度为 $n$ 的输入,而电路族中的 $C_n$ 也专门处理长度为 $n$ 的输入
图灵机 $M$ 在长度为 $n$ 的输入上的计算,可以由一个具有 $n$ 个输入节点的单个电路模拟。若 $t(n)$ 是机器 $M$ 在长度为 $n$ 输入上的运行时间上界,则该电路规模可粗略估计为:
其中,$|\langle M \rangle|$ 是图灵机 $M$ 的描述长度
这种使用布尔电路表述的好处在于,它不需要像机器序列表述那样分别对机器描述长度和运行时间提出两次多项式限制,只需要用电路规模的多项式界来刻画即可
推导:电路规模上界
对于长度为 $n$ 的输入,初始时占用图灵机 $n$ 个磁带格,图灵机每运行一步,磁头最多移动一格,因此运行 $t(n)$ 步后,最多额外访问 $t(n)$ 个位置。于是,整个计算过程中需要关心的磁带区域长度至多是:
图灵机某一时刻的完整信息称为一个配置,每一步的配置的长度可粗略记为:
为了用布尔电路模拟图灵机的计算,可以把图灵机的整个运行过程按时间展开:第 0 步配置、第 1 步配置,直到第 $t(n)$ 步配置。每一层电路负责根据上一时刻的配置计算下一时刻的配置。因此,模拟整个计算过程所需的电路规模可粗略估计为:
由于 $t(n)\leq |\langle M \rangle| + n + t(n) = S$,所以:
于是可以得到更粗略的电路规模上界:
因此,这里的平方上界来自把图灵机的时间计算过程展开成电路层的过程:图灵机运行 $t(n)$ 步,电路就用大约 $t(n)$ 层来模拟,每一层处理一个大小约为 $S$ 的配置,所以总电路规模可由 $O(t(n)\cdot S)$ 控制,并进一步粗略估计为平方上界 $O(S^2)$

