【概述】
IPv4 协议,是现在普遍使用的 IP 协议,其版本号为 $4$,常简称为 IP 协议
该协议定义数据传送的基本单元及其确切的数据格式,同时定义了一套指明分组如何处理、错误如何控制、非可靠传输、分组路由选择的规则
IP 协议的数据传送基本单元被称为 IPv4 数据报,也常被称为 IP 分组、IP 数据报
【IP 数据报格式】
一个 IP 数据报由首部、数据两部分构成,其中,首部分为所有 IP 数据报必须具有的长度为 $20B$ 的固定部分,以及用来提供错误检测、安全机制等功能的长度可变的可变部分
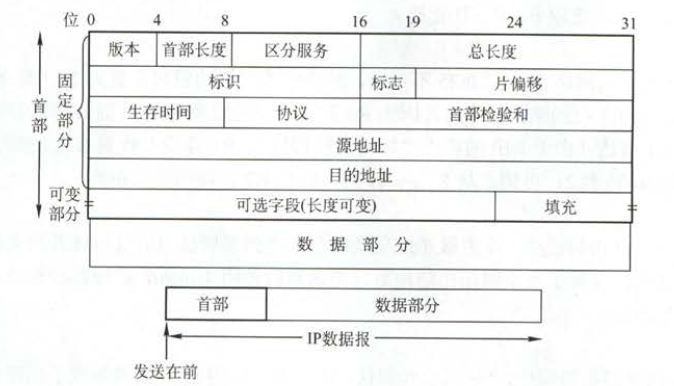
如上图所示,其指明了一个 IP 数据报的具体字段,各字段的含义说明如下:
1.版本
IP 协议的版本,对于 IPv4 数据报来说,其版本号为 $4$
2.首部长度
该字段长度为 $4bit$,用来表示 IP 数据报首部的长度,单位是 $32bit=4B$,故该字段的最大值,即首部最大长度为:
由于 IP 数据报的首部部分的固定部分长度为 $20B$,因此,该字段的最小值为 $5$
进一步可知,可变部分的长度最大为 $40B$
目前最常用的首部长度是 $20B$,也就是说不占用任何可选部分
3.区分服务
又被称为服务类型,指示期望获得哪种类型的服务(例如某些 IP 数据报需要进行优先转发)
目前 IPv4 一般不使用该字段
4.总长度
该字段长度为 $16bit$,用来表示 IP 数据报的总长度,单位是 $B$,故该字段的最大值,即 IP 分组最大长度为:
由于以太网帧的最大传送单元 MTU 为 $1500B$,因此,当一个 IP 数据报封装成帧时,若 IP 数据报的总长度大于 MTU,则需要进行分片处理,以防止超过链路层的 MTU 值
5.标识
该字段长度为 $16bit$,是一个循环计数器,网络中每产生一个数据报就加 $1$
其作用是用来标识分片处理后的 IP 数据报是否为同一数据报
具体来说,当 IP 数据报的总长度大于链路层 MTU 时,需要进行分片处理,同时,对于分片后的每个 IP 数据报,都将会赋予分片前的标识号,这样当 IP 数据报到达目的地址后,根据每个 IP 数据报的标识字段进行重装,标识字段相同的 IP 数据报说明在分片前属于同一 IP 数据报
6.标志
该字段长度为 $3bit$,用于表示分片情况
该字段的中间位用来表示当前数据报能否进行分片,被称为 DF 标志位,即 Don’t Frame
DF=1:不允许分片DF=0:可以分片
最低位用来表示当前数据报后是否还有分片的数据报,被称为 MF 标志位,即 More Frame
MF=1:当前数据报后还有分片MF=0:当前数据报位最后一个分片
需要说明的是,仅当 DF=0 时,MF 标志位才有意义,当 DF=1 时,MF 标志位无意义
7.片偏移
该字段长度为 $13bit$,其指出了较长的分组在分片后,某片在原分组的相对位置
该字段以 $64bit=8B$ 作为偏移单位,即除去最后一个分片外,每个分片的长度一定是 $8B$ 的整数倍
8.生存时间
生存时间(Time To Live,TTL),该字段长度为 $8bit$,用来表示当前数据报在网络中可以通过的路由器数量的最大值
路由器在转发分组前,会将 TTL 先减 $1$,再进行传输,若 TTL 被减为 $0$,则该分组会直接丢弃
TTL 标识了数据报在网络中的寿命,以确保数据报不会在网络中无限制传输
9.协议
该字段占 $8bit$,用于标识当前数据报携带的数据是何种协议,即数据报的数据部分应该交付给哪种传输层协议
例如:值为 $6$ 标识 TCP 协议,值为 $17$ 表示 UDP 协议
10.首部检验和
该字段占 $16bit$,用于 IP 数据报的首部校验
需要注意是,IP 数据报每经过一个路由就需要重新校验一次
11.源地址
该字段占 $32Bit=4B$,用于标识发送方的 IP 地址
12.目的地址
该字段占 $32Bit=4B$,用于标识接收方的 IP 地址
13.可选字段
该字段可占 $0-40B$,是 IPv4 中的一些可选功能,包括排错、测量、安全控制等措施
14.填充
在使用可选字段后,首部长度可能不足以满足 $4B$ 的整数倍,因此可利用该字段进行填充,以保证首部长度为 $4B$ 的整数倍
【IP 数据报分片】
MTU 与分片处理
一个数据链路层的数据报可承载的最大数据量被称为最大传送单元 MTU
由于 IP 数据报被封装在链路层数据报中,因此链路层数据报严格地限制着 IP 数据报的长度
同时,在 IP 数据报从源端到目的端的路径上的各段链路可能使用不同的链路层协议,这也就导致着不同的链路上有着不同的 MTU,例如以太网的 MTU 为 $1500B$,广域网的 MTU 一般不超过 $576B$
因此,在传输过程中,若 IP 数据报的总长度大于链路的 MTU 时,就需要进行分片处理,即将 IP 数据报中的数据进行分割,分装到若干较小的 IP 数据报中,这些若干较小的 IP 数据报,每个被称为片
分片实例
每当源主机创建一个新的 IP 数据报,都会为该数据报的标识字段赋予一个新的标识号,具体规则是在原来的标识号上加 $1$
当一个路由器需要对一个数据报分片时,形成的每片都具有原始数据报的标识号
这样当目的主机收到数据报后,可以通过检查数据报的标识号来确定哪些数据报属于同一个原始数据报
同时,还使用标志字段来说明是否存在分片,利用片偏移来确定片放在原始 IP 数据报的哪个位置
举例来说,现在存在一个首部长 $20B$,数据长 $3980B$,总长 $4000B$ 的 IP 数据报到达一个路由器,该数据报的标识号为 $777$,其要转发到一条 MTU 为 $1500B$ 的链路上
这意味着原始数据报中 $3980B$ 的数据部分需要进行分片处理,总共被分为 $3$ 个片,那么分成的 $3$ 片如下图所示
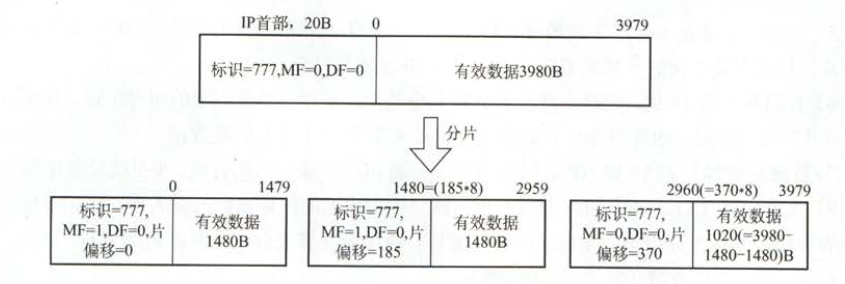
可以看出,由于片偏移的单位是 $8B$,因此除最后一个片外,其他所有片中的有效数据均为 $8B$ 的倍数

