【概述】
RFC 768 定义的 UDP 只是做了传输协议能做的最少工作,只在 IP 数据报服务之上提供了两个最基本的服务:复用与分用、差错检测
因此,如果应用程序开发者选择了 UDP,那么应用程序几乎是直接与 IP 数据报服务打交道,之所以很多应用选择使用 UDP,主要是因为 UDP 具有以下优点:
- UDP 无需建立连接,不会引入建立连接的时延
- UDP 不维护连接状态,一般能够支持更多的活动客户机
- UDP 分组首部开销小,仅有 $8B$ 的开销
- UDP 没有拥塞控制,应用层能够更好地控制要发送的数据与发送时间
【UDP 的特点】
1)UDP 的开销小
由于开销小,因此 UDP 常用于一次性传输较少数据量的应用,如 DNS、SNMP 等
对于这些应用,若采用 TCP,则会因为建立连接、维护连接、拆除连接带来不小的开销
2)UDP 的实时性较好
其也常用于实时性较高的多媒体应用,如视频会议、IP 电话等
3)UDP 提供尽最大努力的交付
UDP 尽最大努力交付,即不保证可靠传输,但这并不意味着应用对数据的要求是不可靠的
因此,所有维护传输可靠性的工作由用户在应用层来完成,应用实体根据应用的需求来灵活设计自己的可靠性机制
4)UDP 服务是面向报文的
报文不可分割,是 UDP 数据报处理的最小单位
发送方 UDP 对应用层交付下来的报文,在添加首部后就向下交付给 IP 层,即不合并也不拆分,之前保留这些报文的边界;接收方 UDP 对 IP 层上交的 UDP 数据报,在去除首部后就原封不动的交付给上层应用,一次性交付一个完整的报文
【UDP 数据报】
UDP 数据报包含两个部分:UDP 首部、用户数据,其中 UDP 首部长度只有 $8B$,整个 UDP 数据报作为 IP 数据报的数据部分封装在 IP 数据报中
在计算 UDP 数据报的检验和时,会添加一个长度为 $12B$ 的伪首部,这个伪首部仅用于计算检验和,并不实际参加数据传输
下图给出了 UDP 数据报的格式
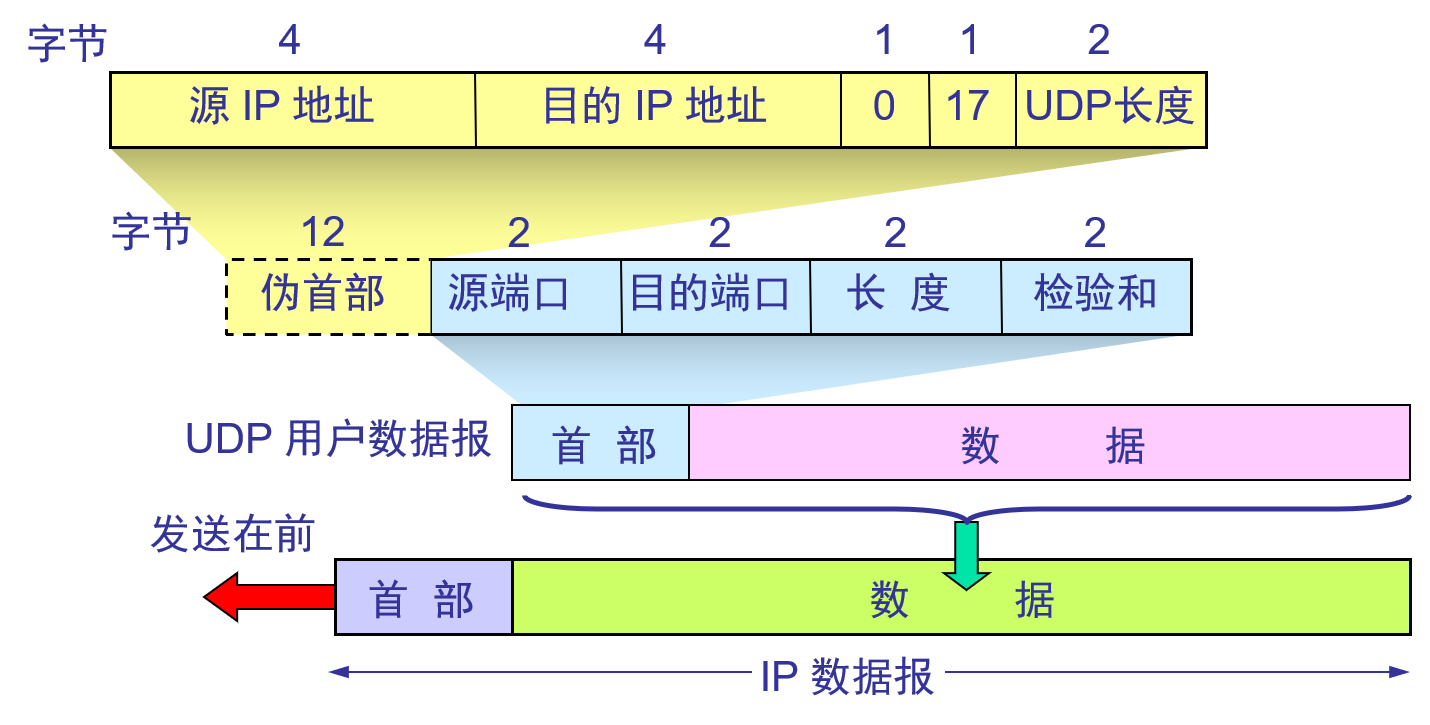
其中,各字段含义如下:
- 源端口:源端口号,在需要对方回信时使用,不需要时一般设为全 $0$
- 目的端口:目的端口号,在终点交付报文时必须使用
- 长度:包含 UDP 首部和用户数据的整个 UDP 数据报的长度,其最小值为 $8$,此时整个 UDP 数据报仅有 UDP 首部
- 检验和:检测 UDP 数据报在传输过程中是否出错,该字段是可选的,当源主机不想计算检验和时,直接令该字段值为全 $0$
【UDP 复用与分用】
在 UDP 协议中,复用,发送方不同的应用进程,都可使用同一个传输层协议传输数据;分用,接收方的传输层,在剥去报文首部后,能将数据交付给目的进程
在实现分用时,依据的是 UDP 首部的目的端口号;在实现复用时,依据的是 UDP 首部的源端口号
下图给出了 UDP 基于端口的复用、分用示意图
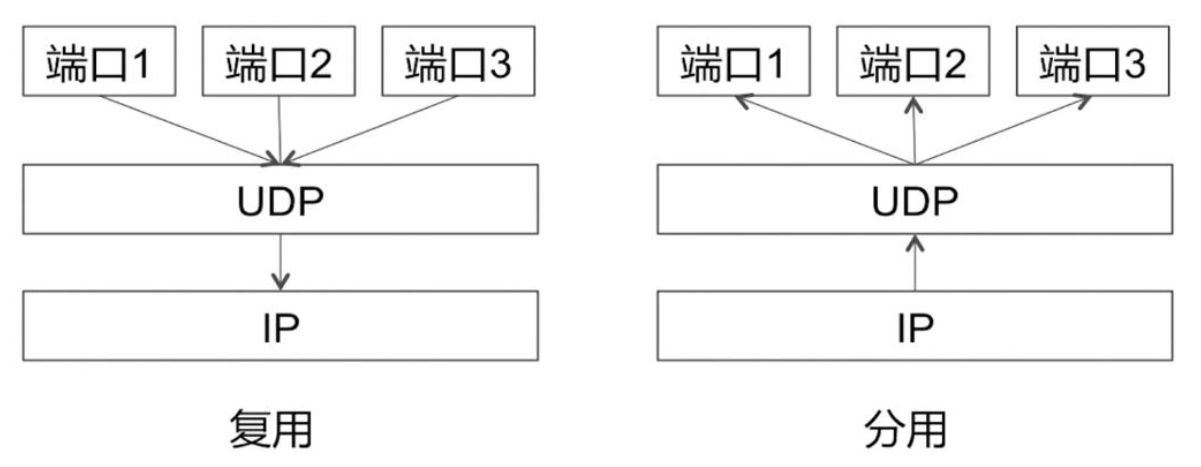
当接收方传输层从 IP 层收到 UDP 数据报后,会根据 UDP 首部中的目的端口,将 UDP 数据报通过相应的端口上交给应用进程
如果接收方发现收到的 UDP 报文中的目的端口号不正确,即发现不存在对应端口号的应用进程,就丢弃该报文,并通过 ICMP 协议发送端口不可达差错报文给发送方
【UDP 差错检验】
在发送方计算检验和时,会添加如上图中的长度为 $12B$ 的伪首部
之后,会将整个 UDP 数据报以 $16bit$ 分为一组,对所有的组通过二进制反码运算求和
最后将计算结果求反码,装填到 UDP 首部的检验和字段中
若整个 UDP 数据报不是 $2B$ 的整数倍,则将会在 UDP 数据报的数据尾部填充 $0$,以用于计算检验和
下图给出了一个计算 UDP 检验和的例子

在接收方接收到 UDP 数据报后,会同样添加 $12B$ 的伪首部,并按照上述过程进行校验,若得出的检验和为全 $1$,则说明无差错
若发现 UDP 数据报出错,可以直接丢弃,也可以交付给上层,但在交付给上层时,需要附上错误报告,即告知上层这是错误的 UDP 数据报
UDP 校验的差错检验方法的检错能力并不强,但这种方法简单、处理速度快

