【概述】
当提及机器学习时,一般指的是统计机器学习(Statistical Machine Learning),其也被称为统计学习(Statistical Learning),即利用数据来构建统计模型,并运用模型对数据进行预测和分析的学科
【形式化】
统计学习方法包括:模型的假设空间、模型的选择准则、求解最优模型的算法,这三者被称为统计学习三要素,即:模型(Model)、策略(Strategy)、算法(Algorithms)
简单来说,在确定模型的假设空间后,需要依照一定的标准在假设空间中选取一个最优模型,依照的标准即模型的选择准则,而选取最优模型的需要通过一定的算法来求解出,这个算法即求解最优模型的算法
基于上述的三要素,统计学习的实现步骤如下:
- 获取一个有限的训练数据集
- 确定模型(确定模型的假设空间)
- 确定策略(确定模型的选择准则)
- 实现算法(设计选择最优模型的算法)
- 通过学习方法(即第 2、3、4 步)来选择一个最优模型
- 通过第 5 步得出的最优模型,对新的数据集进行预测、分析
如下图,假设训练集中有 $N$ 个数据,学习系统包含第 2、3、4 步过程的实现,模型为第 5 步得出的最优模型,即预测系统
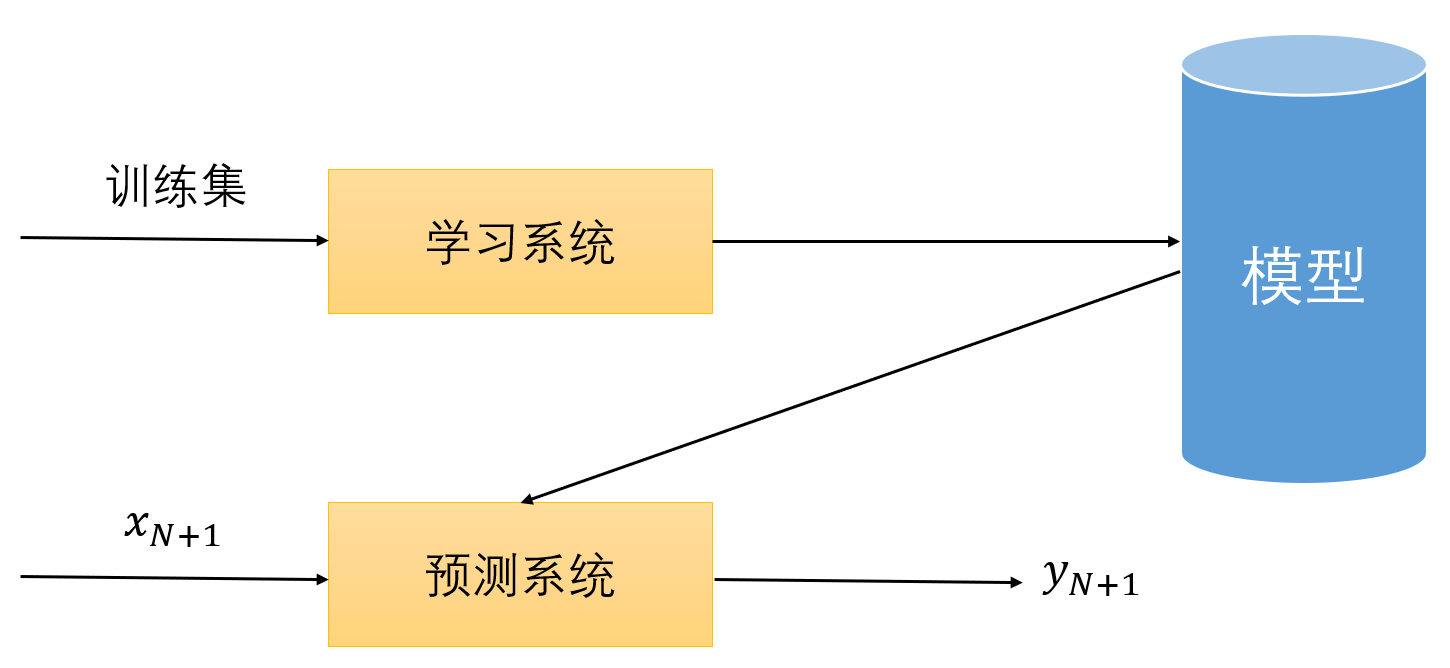
将训练集输入到学习系统中,通过学习系统不断地学习,得到了一个最优模型(预测系统),当输入一个新的实例 $\mathbf{x_{N+1}}$ 时,通过预测系统即可得到输出 $\mathbf{y_{N+1}}$,即对于新数据的预测和分析
【分类】
机器学习可以按照任务、模型、处理过程等进行分类
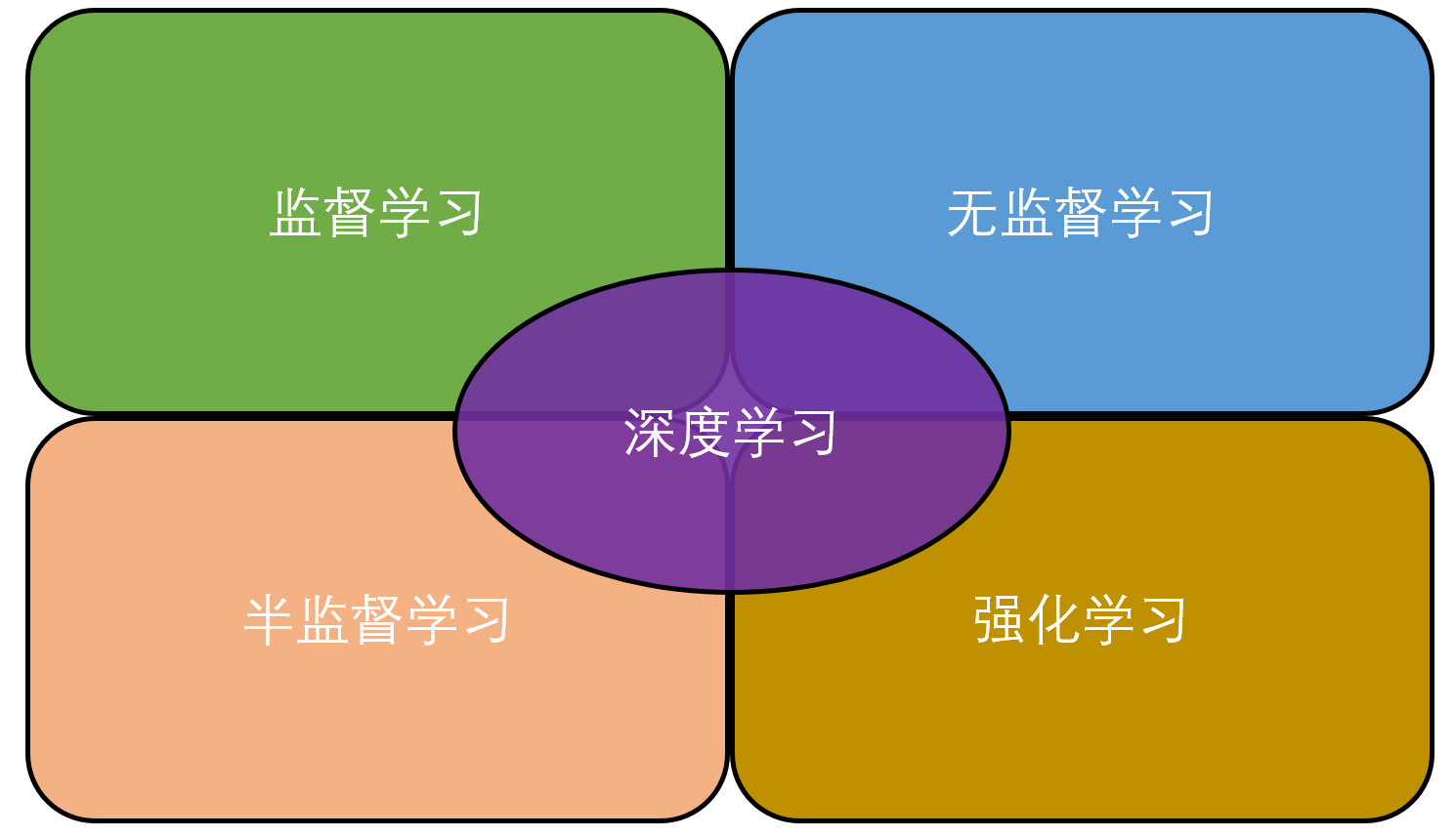
若按任务分类,可分为:监督学习、无监督学习、半监督学习、强化学习
需要说明的是,深度学习是根据模型的结构上的差异化形成的机器学习的一个分支,而其它四类是连接主义学习的四大类别,深度学习跟四类都是有都分重叠关系
若按模型分类,可分为:
- 概率模型与非概率模型
- 概率模型:用条件概率分布表达的模型,例如:决策树、朴素贝叶斯等
- 非概率模型:用函数表达的模型,例如:感知机、支持向量机、神经网络等
- 线性模型与非线性模型
- 线性模型:模型函数是线性的,例如:线性回归模型、Logistics 回归模型等
- 非线性模型:模型函数是非线性的,例如:神经网络等
- 参数化模型与非参数化模型
- 参数化模型:模型参数维度是固定的,例如:感知机、朴素贝叶斯等
- 非参数化模型:模型参数维度是不固定的,例如:决策树、k 近邻等
若按处理过程分类,可分为:
- 在线学习:每次接受一个输入,然后进行预测,在每次接受样本预测后,不断地去修正、优化模型
- 批量学习:每次接受所有输入,学习后即进行预测

