1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
| import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import LinearSVC
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import StackingClassifier
from sklearn.metrics import confusion_matrix,accuracy_score,classification_report,precision_score,recall_score,f1_score
from matplotlib.colors import ListedColormap
def deal_data():
iris = load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
return X,y
def standard_scaler(X_train,X_test):
sc = StandardScaler()
scaler = sc.fit(X_train)
X_train_std = scaler.transform(X_train)
X_test_std = scaler.transform(X_test)
return X_train_std, X_test_std
def train_model(X_train_std, y_train):
estimators = [
('rf', RandomForestClassifier(n_estimators=10, random_state=42)),
('svr', make_pipeline(StandardScaler(), LinearSVC(random_state=42)))]
model = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression())
model.fit(X_train_std, y_train)
return model
def estimate_model(y_pred, y_test, model):
cm2 = confusion_matrix(y_test,y_pred)
acc = accuracy_score(y_test,y_pred)
acc_num = accuracy_score(y_test,y_pred,normalize=False)
macro_class_report = classification_report(y_test, y_pred,target_names=["类0","类1","类2"])
micro_p = precision_score(y_test,y_pred,average='micro')
micro_r = recall_score(y_test,y_pred,average='micro')
micro_f1 = f1_score(y_test,y_pred,average='micro')
indicators = {"cm2":cm2,"acc":acc,"acc_num":acc_num,"macro_class_report":macro_class_report,"micro_p":micro_p,"micro_r":micro_r,"micro_f1":micro_f1}
return indicators
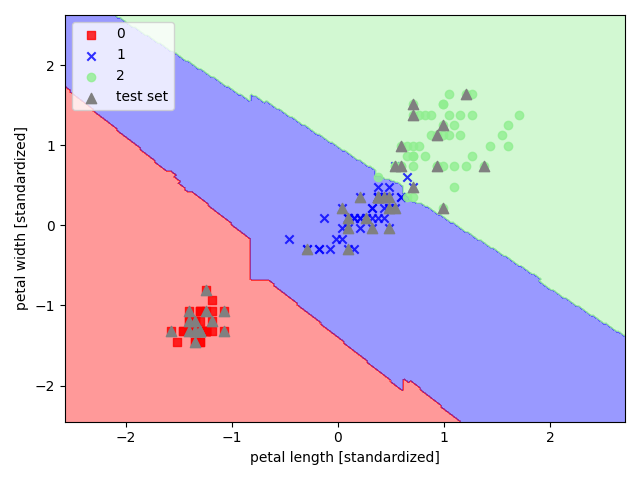
def visualization(X, y, classifier, test_id=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8, c=cmap(idx), marker=markers[idx], label=cl)
if test_id:
X_test, y_test = X[test_id, :], y[test_id]
plt.scatter(x=X_test[:, 0], y=X_test[:, 1], alpha=1.0, c='gray', marker='^', linewidths=1, s=55, label='test set')
plt.xlabel('petal length [standardized]')
plt.ylabel('petal width [standardized]')
plt.legend(loc='upper left')
plt.tight_layout()
plt.show()
if __name__ == "__main__":
X, y = deal_data()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
X_train_std, X_test_std = standard_scaler(X_train, X_test)
model = train_model(X_train_std, y_train)
y_pred = model.predict(X_test_std)
print("y test:", y_test)
print("y pred:", y_pred)
indicators = estimate_model(y_pred, y_test, model)
cm2 = indicators["cm2"]
print("混淆矩阵:\n", cm2)
acc = indicators["acc"]
print("准确率:", acc)
acc_num = indicators["acc_num"]
print("正确分类的样本数:", acc_num)
macro_class_report = indicators["macro_class_report"]
print("macro 分类报告:\n", macro_class_report)
micro_p = indicators["micro_p"]
print("微精确率:", micro_p)
micro_r = indicators["micro_r"]
print("微召回率:", micro_r)
micro_f1 = indicators["micro_f1"]
print("微F1得分:", micro_f1)
X_combined_std = np.vstack((X_train_std, X_test_std))
y_combined = np.hstack((y_train, y_test))
visualization(X_combined_std, y_combined, classifier=model, test_id=range(105, 150))
|