References:
【引入】
使用全连接神经网络,都只能单独的去处理一个个的输入,前一个输入和后一个输入之间没有任何联系的,即输入之间是彼此独立的
但是,某些任务需要能够更好的处理序列信息,即前面的输入和后面的输入是有关系的,例如:
- 当进行翻译任务时,孤立的理解一句话的每个词是不够的,需要处理这些词连接起来的整个序列
- 当分析视频数据时,不能只单独的去分析每一帧,而是要分析这些帧连接起来的整个序列
以 NLP 中最简单的一个词性标注任务举例,假设现在要将 我、吃、苹果 三个单词标注词性为名词、动词、名词,那么这个任务的输入就是已经分词好的句子:我/吃/苹果,相应的输出就是词性标注好的句子:我(名词)/吃(动词)/苹果(名词)
对于这个任务来说,当然可以直接使用全连接神经网络来做,给定的训练数据格式就是:我:我(名词) 这样多个单独的 单词:单词(词性) 标注好的单词
但很明显的是,一个句子中,前一个单词对于当前单词的词性预测是有很大影响的,比如在预测苹果的词性的时候,由于前面的吃是一个动词,那么显然苹果作为名词的概率就会远大于动词的概率,因为动词后面接名词很常见,而动词后面接动词很少见
为了能够更好的处理序列信息,RNN 就诞生了
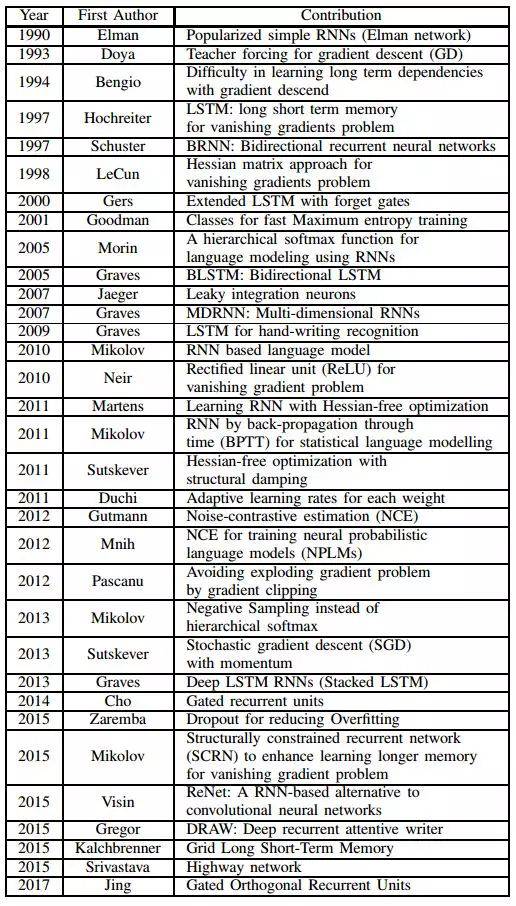
【循环神经网络的发展】
1982 年,John Hopfield 发明了一种单层反馈神经网络 Hopfield Network,用来解决组合优化问题,被认为是循环神经网络(Recurrent Neural Network,RNN)的雏形
1986 年,Jordan 定义了 Recurrent 的概念,提出 Jordan Network,其被认为是最早的 RNN 结构
1990 年,Elman 对 Jordan Network 进行了简化,提出 Elman Network,并采用 BP 算法进行训练,被认为是最简单的包含单个自连接节点的 RNN 模型,但此时 RNN 由于梯度消失与梯度爆炸的问题,训练困难,应用十分受限
1990 年,Werbos 提出了随时间反向传播(Back-Propagation Through Time,BPTT)的 RNN 训练算法,其按照时间序列将 RNN 展开,展开后的网络包含 N(时间步长)个隐含单元和一个输出单元,然后采用反向误差传播方式对神经网络的连接权值进行更新
1997 年,Schuster 在 Elman Network 的基础上提出了双向循环神经网络(Bidirectional Recurrent Neural Networks,BRNN),令输入序列向前、向后分别是两个循环神经网络,且这两个都连接着一个输出层,通过这种双向结构给输出层输入序列中每一个点的完整的过去和未来的上下文信息
1997 年,Hochreiter 在 Elman Network 的基础上提出了长短期记忆单元(Long Short-Term Memory,LSTM),旨在解决时间维度上存在梯度消失问题,同时,使用 LSTM 单元来替换 RNN 中的神经元结点,能够实现较大范围的上下文信息的保存与传输,一定程度上解决了 RNN 结构存储的上下文信息的范围有限的问题,但此时的 LSTM 中并没有遗忘门
2000 年,Gers 在原始的 LSTM 基础上引入了遗忘门,极大的提高了 LSTM 的性能,被认为是最经典的 LSTM 结构
2001 年,Gers 在其提出的 LSTM 结构的基础上加入了窥视孔连接(Peephole Connections),进一步提高了 LSTM 单元对具有长时间间隔相关性特点的序列信息的处理能力,具有窥视孔连接的 LSTM 结构是最流行的 LSTM 结构
2005 年,Graves 提出了双向长短期记忆单元(Bidirectional Long Short-Term Memory,BLSTM),将输入序列分别以正序和逆序输入到两个相互独立的 LSTM 进行特征提取,并将两个提取后的特征向量进行拼接,形成的词向量作为该词的最终表达,使得特征数据同时拥有过去和未来的上下文信息
2014 年,Cho 提出了门控循环单元(Gated Recurrent Units,GRU),其将 LSTM 单元中的输入门、遗忘门、输出门优化成了更新门、重置门,相比 LSTM,使用 GRU 能够达到相当的效果,但其更容易进行训练,能够很大程度上提高训练效率